記事一覧へ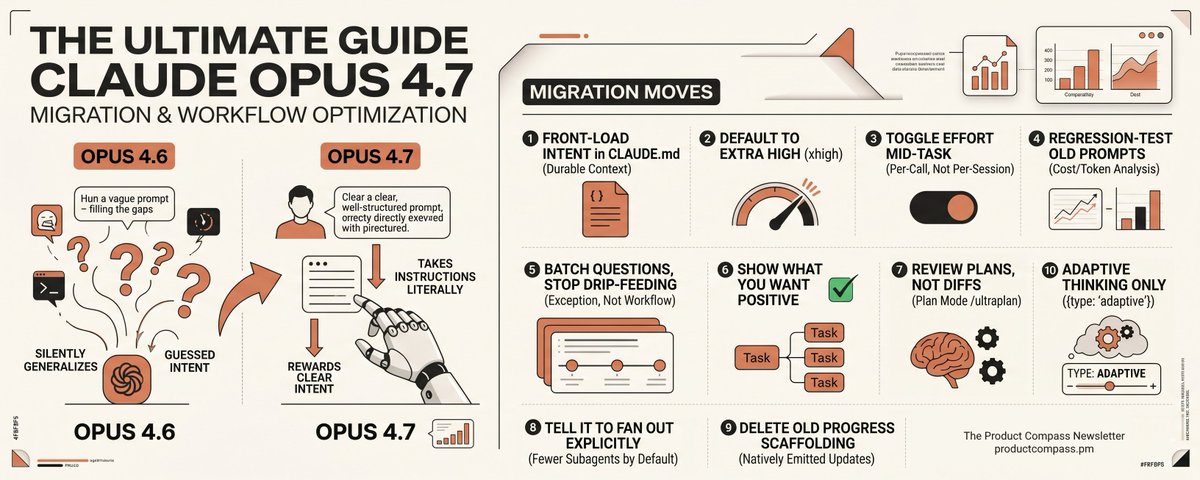
Claude Opus 4.7 完全ガイド
4.6のプロンプトを4.7で機能させる10の手順、コンテキストを先に提示することの重要性、そしてなぜ指示を増やす必要がないのか。
4.6は推測してくれた。4.7は推測をやめた。古いプロンプトはほとんど動く。動かないものは以下の10の手順のどれかが必要だ。
Anthropicは4月16日にClaude Opus 4.7をリリースした。公式移行ガイドには明確に書かれている: 4.7は「指示を文字通りに受け取り」「暗黙の一般化をしない」。
均一なアップグレードではない。コーディング、クリエイティブライティング、構造化作業では改善。曖昧なプロンプトでの指示遵守、マルチターン、長文コンテキスト検索では後退。ベンチマークはトレードオフを示しており、退行ではない。
Claude CodeのリードエンジニアBoris Chernyはリリース当日にこう投稿した: 「効果的に使いこなすまでに数日かかった。」
## 1. Opus 4.7の新機能
4.6は指示が不明確なとき空白を埋めてくれた。4.7はあなたの言葉を額面通りに受け取る。
PMへ: 4.6のワークフローがモデルの「意図を汲み取る能力」に頼っていたなら、4.7はより多くの質問をするか、より少ししかやらないか、あるいはまさにあなたが頼んだことを(それがあなたの望んでいたものでなくても)やるようになるはずだ。
## 2. インテント: 万能の鍵
これが原則だ: 4.7は明確なインテントに報いる。この記事の他すべてはその戦術に過ぎない。
長いプロンプトでも、ルールを増やすことでも、大きなCLAUDE.mdでもない。インテントは2つの層に分かれる:
戦略的コンテキストは持続する: あなたが何を構築しているか、誰のためか、何が禁止事項か、何が良い状態か。一度書けばいい。CLAUDE.md に入れておく。毎セッション自動で読み込まれるので、1ターン目にプロジェクトを再紹介するコストを払わなくて済む。
タスクごとのインテントは変動する: 今Claudeに具体的に何をしてほしいか。これは毎ターン書く。CLAUDE.mdのメリットは戦略的コンテキストを毎回書き直す手間が省けることだ。
Claudeをパートナーとして扱う。何をしているか、なぜしているか、戦略・目標・成功基準を理解させる。エージェントをマイクロマネジメントするのではなく、戦略的コンテキストを提供する。
## 2.1 AnthropicとOpenAIの収束
Anthropicはより文字通りの指示遵守へOpus 4.7を向けた。OpenAIは2025年12月のModel Specを「文字通りの表現だけでなく根本的な意図も考慮する」と更新した。
両社は反対方向から収束している。Anthropicはインテント優先モデルに精度を加えている。OpenAIは精度優先モデルにインテント推論を加えている。同じスキル(インテントを明確にエンジニアリングすること)が両側で鍵になっている。
## 3. Claude Opus 4.7移行の10の手順
### 3.1 CLAUDE.mdにインテントを先出しする
毎セッション戦略的コンテキストを書き直す必要はない。CLAUDE.mdに一度入れておけば、以降のセッションはコンテキストが読み込まれた状態で始まる。
### 3.2 デフォルトをExtra high (xhigh)に
highとmaxの間の新しいeffortレベル。コーディングとエージェント作業に対するAnthropicの推奨設定。
maxは過剰思考になりがちだ。「4.7が遅い」という報告のほとんどは反射的にmaxを実行している人によるものだ。問題が本当に深い推論を必要とする時だけmaxを使う。
### 3.3 タスク途中でeffortを切り替える
effortはセッションではなく呼び出しごとに設定される。難しいサブ問題にはmax。残りはhighに戻す。
### 3.4 古いプロンプトのリグレッションテスト
新しいトークナイザー。入力あたり1.0〜1.35倍のトークン。4.6のワークフローは一行も変えていなくても4.7ではコストが上がる。
### 3.5 質問をバッチにまとめる。小出しをやめる。
3つ質問があれば、1つのメッセージで全部聞く。
4.6では3〜4ターンに分けて明確化しても機能した。4.7では各ターンが前のターンの文字通りの解釈の上に推論オーバーヘッドを加える。
### 3.6 欲しいものを見せる
ポジティブな例はネガティブなルールより効果的。Anthropicによると:
「このように:」に続く短い例は機能する。
「こうしてはいけない:」はほとんど効かず、トークンを無駄に消費する。
### 3.7 古いプログレス足場を削除する
「ツール3回呼んだらまとめて」「次に進む前に状況報告して」を削除する。
Opus 4.7は長いエージェント実行においてネイティブに高品質なプログレス更新を提供する。
### 3.8 ファンアウトを明示的に指示する
Opus 4.7はデフォルトでより少ないサブエージェントを生成し、タスクあたりのツール呼び出しも減った。並列探索のためには明示的に指示が必要だ。
機能するフレーズ: 「同じターンでX、Y、Zを調査するサブエージェントを起動して。」
### 3.9 diffではなくプランをレビューする
プランモード(Claude Code CLIでShift+Tab 2回): インライン、現在のセッションでコードが存在する前にプランを表示。
/ultraplan(CLIのみ): CLIからのクラウドベースのプラン作成、ブラウザでレビュー。
4.7でこれがより重要になった理由: 4.7はインテントを文字通りに受け取るため、プランでの小さな誤解がdiffで大きな誤解になる。インテントのずれを10行のプランで確認するには30秒。同じずれを200行のdiffで確認するには15分かかる。
### 3.10 Adaptive thinkingのみを使う
固定のthinking budgetはなくなった。effortパラメータとともにthinking: {type: 'adaptive'}を使う。budget_tokensを含む古いAPI呼び出しはHTTP 400を返す。
```javascript
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=16000,
thinking={"type": "adaptive"},
messages=[
{
"role": "user",
"content": "Explain why the sum of two even numbers is always even.",
}
],
)
```
## 4. まとめ
4.6は賢く感じた。4.7は誠実だ。知性が落ちたように見えるのは、4.7が推測を拒否しているからだ。
あなたのレバレッジは明確なインテントにある。コードのすべての行をレビューすることでも、無限に指示を書くことでも、毎セッション同じコンテキストを書き直すことでもない。あなたのインテントと期待をCLAUDE.mdに書けば書くほど、それを動かすためのコスト(お金と注意力)が下がる。
claude-workflowclaude-codeopus-4-7harness-design
Claude Opus 4.7完全ガイド:4.6プロンプトを機能させる10の手順
♥ 107↻ 10
原文を表示 / Show original
The Ultimate Guide to Claude Opus 4.7
The ten moves to make your 4.6 prompts work on 4.7, leading with context, and why you don't need more instructions.
4.6 guessed. 4.7 stopped guessing. Your old prompts still work, mostly. The ones that break need one of the ten moves below.
Anthropic shipped Claude Opus 4.7 on April 16. The official migration guide puts it plainly: 4.7 "takes the instructions literally" and "will not silently generalize."
It's not a uniform upgrade. Wins on coding, creative writing, and structured work. Losses on instruction following in vague prompts, multi-turn, and long-context retrieval. The benchmarks show a trade, not a regression.
Boris Cherny, Claude Code lead at Anthropic, posted on release day: "It took a few days for me to learn how to work with it effectively."
## 1. What's New in Opus 4.7
4.6 filled the gaps when your instruction was unclear. 4.7 takes you at your word.
For PMs: if your 4.6 workflow relied on the model "figuring out what you meant," expect 4.7 to ask more questions, or to do less, or to do exactly what you asked for (which is not what you wanted).
## 2. Intent: The Universal Unlock
This is the principle: 4.7 rewards clear intent. Everything else in this post is a tactic.
Not longer prompts, not more rules, not a bigger CLAUDE.md. Intent splits into two layers:
Strategic context is durable: what you're building, who it's for, what's off-limits, what good looks like. Write it once. Put it in CLAUDE.md. It loads every session, progressive-disclosure style, so you're not paying to reintroduce the project on turn one.
Per-task intent is variable: what specifically do I want Claude to do right now. You still write this every turn. The gain from CLAUDE.md is that you stop retyping the strategic context on top of it.
Treat Claude as a partner. Help it understand what and why you're doing, your strategy, objectives, and success criteria. Strategic context - not micromanaging the agent.
## 2.1 Anthropic and OpenAI convergence
Anthropic moved Opus 4.7 toward more literal instruction following. OpenAI updated their December 2025 Model Spec to say "consider not just the literal wording but the underlying intent."
They're converging from opposite directions. Anthropic is adding precision to its intent-first model. OpenAI is adding intent inference to its precision-first model. The same skill (engineering intent clearly) is becoming the unlock on both sides.
## 3. The 10 Claude Opus 4.7 Migration Moves
### 3.1 Front-load intent in CLAUDE.md
You don't have to retype the strategic context every session. Put it in CLAUDE.md once. Every future session starts with the context already loaded.
### 3.2 Default to Extra high (xhigh)
New effort level between high and max. Anthropic's own recommendation for coding and agentic work.
max is prone to overthinking. Most "4.7 feels slow" reports trace back to people running max by reflex. Use max only when the problem actually needs deep reasoning.
### 3.3 Toggle effort mid-task
Effort is per-call, not per-session. max for the hard subproblem. Drop back to high for the rest.
### 3.4 Regression-test old prompts
New tokenizer. 1.0 to 1.35x more tokens per input. Your 4.6 workflows cost more on 4.7 before you've changed a line.
### 3.5 Batch questions. Stop drip-feeding.
If you have three questions, ask all three in one message.
On 4.6, clarifying across 3-4 turns worked. On 4.7, each turn adds reasoning overhead on top of literal interpretations from earlier turns.
### 3.6 Show what you want
Positive examples beat negative rules. According to Anthropic:
"Like this: " followed by short examples works.
"Don't do this: " rarely lands and burns tokens trying.
### 3.7 Delete old progress scaffolding
"Summarize every 3 tool calls." "Give me a status update before moving on." Delete these.
Opus 4.7 emits high-quality progress updates natively in long agentic traces.
### 3.8 Tell it to fan out explicitly
Opus 4.7 spawns fewer subagents by default and makes fewer tool calls per task. For parallel exploration, you now have to ask.
Phrasings that work: "spawn subagents in the same turn to investigate X, Y, Z."
### 3.9 Review plans, not diffs
Plan mode (Shift+Tab twice in the Claude Code CLI): inline, surfaces the plan before any code exists in the current session.
/ultraplan (CLI only): cloud-based plan drafting from the CLI, review in the browser.
Why this matters more on 4.7: because 4.7 takes intent literally, a small misread in the plan becomes a large misread in the diff. Reviewing a 10-line plan for intent drift takes 30 seconds. Reviewing a 200-line diff for the same drift takes 15 minutes.
### 3.10 Adaptive thinking only
Fixed thinking budgets are gone. Use thinking: {type: 'adaptive'} plus the effort parameter. Old API calls with budget_tokens return HTTP 400.
```javascript
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=16000,
thinking={"type": "adaptive"},
messages=[
{
"role": "user",
"content": "Explain why the sum of two even numbers is always even.",
}
],
)
```
## 4. Closing
4.6 felt smart. 4.7 is honest. What looks like less intelligence is 4.7 refusing to guess.
Your leverage is clear intent. Not reviewing every line of code, writing endless instructions, or retyping the same context every session. The more of your intent and expectations you push up to CLAUDE.md, the less you pay (in money and attention) to run the thing.