記事一覧へ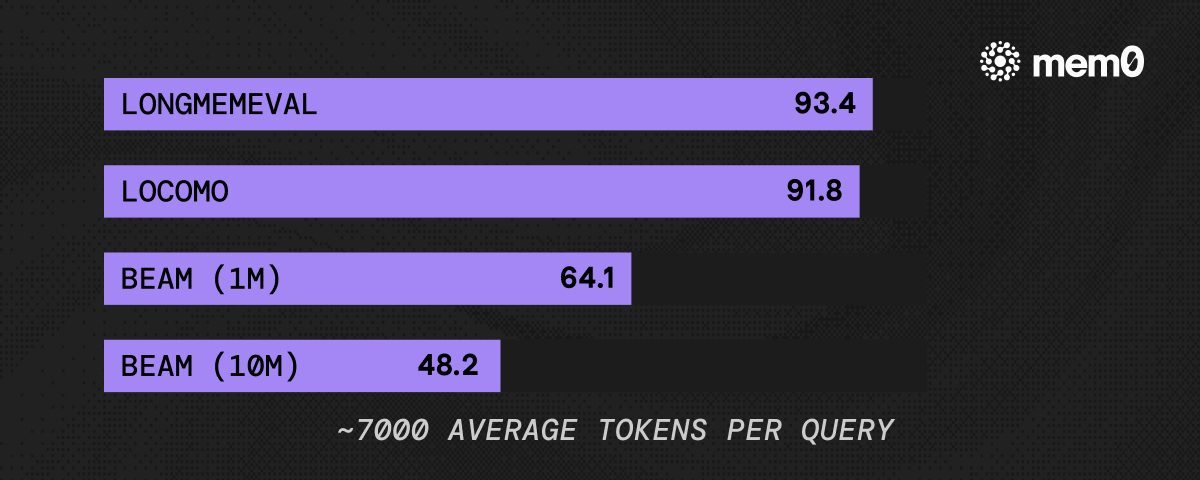
Mem0の新しいメモリアルゴリズムが、LoCoMo、LongMemEval、BEAMにおいて7,000トークン/クエリ未満(約3〜4倍少ない)で競争力のある精度を達成した。ほとんどのシステムが25,000以上で実行しているのと比較して。
完全オープンソース。
仕組みを解説する。
## 実際の環境でのトークン効率
ほとんどのAIエージェントメモリシステムはコンテキストウィンドウサイズを最大化することで情報を取得する。ベンチマークでは機能するが、実際の環境では機能しない。すべてのトークンがコストを増やすからだ。
トークン効率とは、クエリあたりのコンテキストを少なくしながら高い精度を達成することだ。
LoCoMo、LongMemEval、BEAMにわたるベンチマークで、新しいメモリアルゴリズムは7,000トークン未満の取得呼び出しで競争力のある精度を達成した。比較として、これらのベンチマークのフルコンテキストアプローチはクエリあたり25,000以上のトークンを日常的に消費する。
新しいアルゴリズムは今日Mem0プラットフォームとオープンソースSDKの両方で利用可能だ。
## 実際に機能するエージェントメモリの構築
メモリを正しく構築するということは、抽出、取得、推論という3つの問題を同時に解決することを意味する。ほとんどのシステムは取得のみを最適化しているため、そこで頭打ちになる。
この分野での支配的なフレーミング(保存、埋め込み、取得)は、実際に何百万もの相互作用に対してデプロイされたメモリシステムがしなければならないことをキャプチャしていない。2つの例がこのリリースのアーキテクチャ決定を形作った:
2ヶ月間毎週金曜日に同じタイ料理店から注文するユーザーを考えてみよう。取得システムは「3月8日の金曜日にパッタイを注文した」という8つのレコードを保存し、正確に何が起きたかを教えることができる。このユーザーのディナー予約をどこでとるか聞かれると、何も提供できない。優れたメモリシステムは、このユーザーがタイ料理を愛していて金曜夜の定番スポットがあることを数週間前に把握しているべきだ。
あるいは、プロフィールにニューヨーク在住と書かれているユーザーを考えよう。6ヶ月後、新しいデータが彼らがサンフランシスコに引っ越したことを示す。ほとんどのメモリシステムは変化を置き換えとして扱う:古い事実が上書きされる。しかしユーザーがニューヨークからサンフランシスコに引っ越したことを知ることは、現在の都市を知るだけより価値がある。コンテキストを本当に理解するシステムは、両方の事実を保持し、移行があったことを理解し、「旧住所」はニューヨークを指し「現在地」はサンフランシスコを意味することを知るべきだ。
このリリースはMem0を、抽出、取得、推論が独立したステージとしてではなく連携して機能する統合メモリシステムに向けて前進させる。
## 私たちのアプローチ:階層型メモリ
取得はすべての層を並行してスコアリングし、結果をフォーズする。「Aliceのリモートワークについての考えは?」という質問はエンティティマッチングに依存する。「先週どんなミーティングがあったか?」は時間的理解に依存する。「このプロジェクトに対するユーザーの態度はどう変化したか?」は多くの散在したメモリにわたる高次の推論を必要とする。
このリリースでは、既存の文レベルの取得の上にエンティティレベルのマッチングを実装した。次は行動パターンマッチングを追加する予定だ。
抽出と取得は非同期で実行されるため、エージェントは自分のコンテキストを管理するサイクルを燃やさない。
## 変更点
### 1. シングルパス、ADDのみの抽出
古いアルゴリズムは2回のLLMパスでメモリを抽出していた。最初のパスで入力から候補事実を特定した。2回目のパスで、ADD、UPDATE、DELETE操作を使って既存メモリとそれらの事実を照合した。この照合ステップは遅く、コンテキストが破壊される場所だった。上書きは元の事実から重要な情報を消すことがあった。削除は後で関連するかもしれない情報を削除することがあった。
一般的に、メモリシステムは変化を置き換えとして扱う。何か新しいことが起きると、古い事実が上書きされ、情報が捨てられる。ADDのみの抽出は状態変化の完全な履歴を保存するため、システムはどこに着地したかだけでなく、どのように進化したかを推論できる。
新しいアルゴリズムは抽出を追加のみの単一LLM呼び出しに折りたたむ。抽出されたすべての事実が独立したレコードになる。情報が変化すると、新しい事実は古い事実と共存し、両方が残る。これにより抽出のレイテンシが約半分になり、より良いメモリを生み出す。なぜならモデルは既存の状態とdiffするのではなく、入力を理解することにその能力を費やすからだ。
### 2. エージェント生成事実のファーストクラス化
Mem0は今、エージェント生成事実をファーストクラスとして扱う。以前は、エージェントが「3月3日のフライトを予約しました」と言うと、古いシステムはしばしばそれを完全に無視し、ユーザーが明示的に述べたことだけに注目していた。
新しいアルゴリズムは、アクションの確認や推薦の提供などのエージェント生成事実を同等の重みで保存し、メモリカバレッジの重要なギャップを埋める。
### 3. エンティティリンキング
すべてのメモリは今、固有名詞、引用テキスト、複合名詞句を含むエンティティを分析される。これらのエンティティは埋め込まれ、同じ人物、場所、概念についてのメモリをリンクする別の検索レイヤーに保存される。クエリ時に、クエリから特定されたエンティティがこのレイヤーと照合され、関連するメモリがランキングブーストを受ける。
### 4. マルチシグナル取得
取得スタックは意味的類似性、キーワードマッチング、エンティティマッチングの3つのスコアリングパスを並行して実行し、結果をフョーズする。異なるクエリは異なるシグナルに依存し、結合スコアは個別のシグナルスコアを上回る。
### 5. キーワード正規化
「先週参加したミーティングは?」のようなクエリが「ミーティングに参加している」というメモリに一致しないことがあった。なぜならキーワード検索が活用の変形を異なるトークンとして扱っていたからだ。動詞形の正規化がこれを修正する。
## 結果
すべての結果は古いアルゴリズムと新しいアルゴリズムを比較し、シングルパス取得セットアップ(1回の取得呼び出し、1回の回答、エージェントループなし)を使用している。
### LoCoMo
LoCoMoは会話セッションにわたる単一ホップ、マルチホップ、オープンドメイン、時間的メモリ再現をテストする。
平均トークン:6,950
最大の改善は時間的クエリ(+29.6)とマルチホップ推論(+23.1)だ。開発者にとって、これは「ユーザーが初めてXについて言及したのはいつか?」や「ユーザーの現在の決定につながったのは何か?」などの質問をより確実に処理できることを意味する。
### LongMemEval
LongMemEvalは知識更新と時間的推論を含むシングルセッションとマルチセッションコンテキストにわたるメモリを評価する。
平均トークン:6,787
最大の改善はシングルセッションアシスタント(+53.6)、時間的推論(+42.1)、知識更新(+16.7)だ。アシスタントメモリ再現の向上は、新しいシステムがエージェントが言ったことを確実に覚えることを意味する。
### BEAM
BEAMは1Mと10Mトークンスケールで、好み遵守、時間的推論、矛盾解消を含む10のタスクカテゴリにわたってメモリシステムを評価する。
平均トークン(1M):6,719
平均トークン(10M):6,914
パフォーマンスは10Mより1Mの方が意味的に強い。10Mスケールでは、ウィンドウ全体で類似コンテンツが何度も現れるため取得が難しくなり、メモリシステムは常に他の近いマッチより正確なメモリを表面化できない。
好み遵守、命令遵守、知識更新ではシステムが両方のスケールで良いパフォーマンスを示す。10Mで弱いカテゴリは時間的推論、イベント順序付け、マルチセッション推論だ。これらは分野全体でオープンな問題だ。
## 次のステップ
現在のシステムの主な制限は、最も難しい長距離メモリタスクには事実レベルとエンティティレベルの取得がまだ不十分なことだ。次の研究対象:
- より豊かな時間的表現
- クロスセッションイベント構造のより良いモデリング
- より表現力豊かな取得フィョーズ
- エージェントワークフローとの密接な統合
このリリースは実際のトークン予算の下で抽出効率と取得品質を改善する。残りの課題は時間とともに情報がどのように変化するかを表現し、大規模でその構造を確実に使用することだ。
GitHub | 評価リポジトリ | 研究 | ドキュメント
Mem0はLLMとAIエージェントのためのインテリジェントなオープンソースメモリレイヤーで、セッションを超えた長期的でパーソナライズされた、コンテキスト対応のインタラクションを提供するよう設計されている。
無料APIキーはこちら:app.mem0.ai
またはオープンソースGitHubリポジトリからself-hostする
agent-opsai-thinkingharness-design
Mem0新アルゴリズム:7K tokens精度
♥ 88↻ 13
原文を表示 / Show original
New @mem0ai memory algorithm hits competitive accuracy across LoCoMo, LongMemEval, and BEAM at <7,000 tokens/query (≈3–4x fewer tokens), while most systems run at 25,000+.
Fully open source.
We break down how it works ↓
Most AI agent memory systems retrieve information by maximizing context window size. That works on benchmarks but does not work in production, where every token adds cost. Token efficiency means achieving high accuracy with less context per query.
Our new memory algorithm, benchmarked across LoCoMo, LongMemEval, and BEAM, achieves competitive accuracy while using under 7,000 tokens per retrieval call. For comparison, full-context approaches on these benchmarks routinely consume 25,000+ tokens per query.
The new algorithm is available today on both the Mem0 platform and the open-source SDK.
Mem0 new algorithm summary (April 2026)
Table 1: Mem0's accuracy(%) on various benchmark.
Building agent memory that works in practice
Getting memory right means solving three problems at once: extraction, retrieval, and reasoning. Most systems only optimize retrieval, which is why they plateau. The dominant framing in this space (store, embed, retrieve) does not capture what a memory system deployed against millions of real interactions has to do. Two examples shaped the architecture decisions in this release:
Consider a user who orders from the same Thai restaurant every Friday for two months. A retrieval system stores eight records of "Ordered pad thai on Friday" and can tell you exactly what happened on March 8th. If you ask where to book a dinner reservation for this user, it has nothing to offer. A good memory system should have figured out weeks ago that this person loves Thai food and has a go-to Friday night spot.
Or consider a user whose profile says they live in New York. Six months later, new data indicates they have moved to San Francisco. Most memory systems treat change as replacement: the old fact gets overwritten. But knowing that a user moved from New York to San Francisco is more valuable than just knowing their current city. A system that actually understands context should retain both facts, understand there was a transition, and know that references to "your old neighborhood" point to New York while "your current location" means San Francisco.
This release advances Mem0 toward a unified memory system where extraction, retrieval, and reasoning work together rather than as independent stages.
Our approach: hierarchical memory
Retrieval scores all layers in parallel and fuses the results. A question like "what does Alice think about remote work?" leans on entity matching. "What meetings did I have last week?" depends on temporal understanding. "How has the user's attitude toward this project shifted?" requires higher-order reasoning across many scattered memories.
This release ships entity-level matching on top of existing sentence-level retrieval. We plan to add behavioral pattern matching next.
Extraction and retrieval run asynchronously, so agents are not burning cycles managing their own context.
What changed
1. Single-pass, ADD-only extraction
The old algorithm extracted memories in two LLM passes. The first identified candidate facts from the input. The second reconciled those facts against existing memories using ADD, UPDATE, and DELETE operations. That reconciliation step was slow, and it was where context got destroyed. Overwrites sometimes erased key information from the original fact. Deletes sometimes removed information that would be relevant later.
Generally, memory systems treat changes as replacements. When something new happens, the old fact gets overwritten, which throws away information. ADD-only extraction preserves the full history of state changes, so the system can reason about how things evolved, not just where they landed.
The new algorithm collapses extraction into a single LLM call that only adds. Every extracted fact becomes an independent record. When information changes, the new fact lives alongside the old one, and both survive. This cuts extraction latency roughly in half and produces better memories, because the model spends its capacity on understanding the input rather than diffing against existing state.
2. Agent-generated facts are now first-class
Mem0 now treats agent-generated facts as first-class. Previously, when an agent said something like "I've booked your flight for March 3," the old system would often ignore it entirely and focus only on what the user explicitly stated.
The new algorithm stores agent-generated facts like confirming an action or providing a recommendation, with equal weight, closing a significant gap in memory coverage.
Fig 1: Memory extraction. Input flows through context lookup, single-pass extraction, deduplication, and entity linking before being written to persistent storage.
3. Entity linking
Every memory is now analyzed for entities, including proper nouns, quoted text, and compound noun phrases. These entities are embedded and stored in a separate lookup layer, linking memories about the same person, place, or concept. At query time, entities identified from the query are matched against this layer, and relevant memories receive a ranking boost.
4. Multi-signal retrieval
The retrieval stack runs three scoring passes in parallel, semantic similarity, keyword matching, and entity matching, and fuses the results. Different queries lean on different signals, and the combined score outperforms individual signal scores.
Fig 2: Multi-signal retrieval stack. Queries are preprocessed and scored in parallel across semantic, keyword, and entity signals, then fused via rank scoring.
5. Keyword normalization
Queries like "what meetings did I attend?" were failing to match memories containing "attending a meeting" because the keyword search treated conjugation variants as different tokens. Verb form normalization fixes this. This is a small change with measurable impact.
Results
All results compare the old algorithm against the new one, using a single-pass retrieval setup: one retrieval call, one answer, no agentic loops. Scores carry a ±1 point confidence interval due to judge inconsistency.
Scores reflect Mem0's managed platform, which includes proprietary optimizations not available in the open-source SDK. Open-source users should expect directionally similar gains but not identical numbers. The full evaluation framework is open-source so anyone can reproduce the numbers independently.
How to interpret these numbers
Evaluating a memory system at scale comes down to 3 parameters:
accuracy (what the benchmarks measure),
cost (context tokens per query), and
performance (latency).
Optimizing one of them is easy, but balancing all three at scale is the actual problem.
Some benchmarks today, particularly smaller ones like LoCoMo and LongMemEval, can be materially improved by aggressive retrieval strategies, larger context windows, or frontier models. That does not necessarily mean the underlying memory system has gotten better. Our goal was to test under constraints that reflect how memory systems actually run in production: limited context windows and practical token budgets.
BEAM is the most relevant benchmark here. It operates at 1M and 10M token scales and cannot be solved by simply expanding the context window. The results at 10M reflect where memory systems actually stand at production context volumes.
LoCoMo
LoCoMo tests single-hop, multi-hop, open-domain, and temporal memory recall across conversational sessions.
All results compare the old algorithm against the new
Mem0 new algorithm results on LoCoMo (April 2026):
Table 2: LoCoMo Results (Mem0 - April 2026)
Mean tokens: 6,95
The two biggest gains are on temporal queries (+29.6) and multi-hop reasoning (+23.1). For a developer, this means the new algorithm handles questions like "when did the user first mention X?" or "what led to the user's current decision?" much more reliably. Both categories directly test the ADD-only architecture and the entity linking layer.
LongMemEval
LongMemEval evaluates memory across single-session and multi-session contexts, including knowledge updates and temporal reasoning.
Mem0 new algorithm results on LongMemEval (April 2026):
Table 3: LongMemEval Results (Mem0 - April 2026)
Mean tokens: 6,787
The biggest gains are on single-session assistant (+53.6), temporal reasoning (+42.1), and knowledge updates (+16.7). The jump on assistant memory recall means the new system reliably remembers things your agent said. That is the kind of thing developers assume will just work until they actually test it. The old algorithm had a blind spot for agent-generated facts that the new one does not.
The 100.0 on single-session assistant reflects a small evaluation set where a targeted fix resolved the category.
BEAM
BEAM evaluates memory systems at 1M and 10M token scales across ten task categories, including preference following, temporal reasoning, and contradiction resolution. It is the only public benchmark that operates at context volumes production AI agents actually encounter.
Mem0 new algorithm results on BEAM (April 2026):
Table 4: BEAM Results (Mem0 - April 2026)
Mean tokens (1M): 6,719
Mean tokens (10M): 6,914
Performance is meaningfully stronger at 1M than at 10M. At 10M scale, retrieval gets harder because similar content appears multiple times across the window, and the memory system cannot always surface the exact correct memory over other close matches.
Looking at the category breakdown, the system holds up well on preference following, instruction following, and knowledge updates at both scales. These tasks benefit from the ADD-only architecture retaining state cleanly over long horizons. The weaker categories at 10M are temporal reasoning, event ordering, and multi-session reasoning. These are open problems across the field. Fact-level and entity-level matching are not sufficient for them. They require higher-order representations of how events relate to each other across time, and that is a primary focus of our ongoing research.
What's next
The main limitation of the current system is that fact-level and entity-level retrieval are still insufficient for the hardest long-range memory tasks. The weakest areas remain temporal reasoning, event ordering, and multi-session reasoning at large scales. The next areas of work are:
richer temporal representations
better modeling of cross-session event structure
more expressive retrieval fusion
tighter integration with agent workflows
This release improves extraction efficiency and retrieval quality under practical token budgets. The remaining work is in representing how information changes over time and using that structure reliably at larger scales. If this is the kind of systems problem excites you, come work with us.
GitHub | Evaluation repository | Research | Docs
mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here : app.mem0.ai
or self-host mem0 from our open sourcegithub repository