記事一覧へ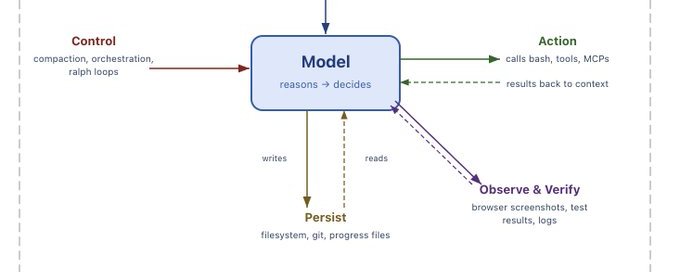
エージェントハーネスはエージェント構築の主流な方法になりつつあり、なくなることはありません。これらのハーネスはエージェントのメモリと密接に結びついています。クローズドなハーネスを使っている場合—特にプロプライエタリなAPIの後ろにある場合—エージェントのメモリのコントロールをサードパーティに委ねることを選択しています。メモリは優れた粘着性のあるエージェント体験を生み出すために非常に重要です。これは強力なロックインを生み出します。メモリ—そしてハーネス—はオープンであるべきで、そうすることで自分自身のメモリを所有できます。
## エージェントハーネスはエージェントの構築方法であり、なくなることはない
エージェントシステムを構築する「最良の」方法は、過去3年間で劇的に変化しました。ChatGPTが登場したとき、できることはシンプルなRAGチェーン(LangChain)だけでした。次にモデルが少し良くなり、より複雑なフロー(LangGraph)が作れるようになりました。そして大幅に良くなり、新しいタイプのスキャフォールディング—エージェントハーネス—が生まれました。
エージェントハーネスの例としては、Claude Code、Deep Agents、Pi(OpenClawを駆動)、OpenCode、Codex、Letta Codeなどがあります。
💡エージェントハーネスはなくなりません。
モデルがどんどんスキャフォールディングを吸収するという意見があることがあります。これは正しくありません。実際に起きたこと(そしてこれからも起きること)は、2023年に必要だったスキャフォールディングの多くがもはや必要でなくなったということです。しかしこれは他のタイプのスキャフォールディングに取って代わられました。エージェントは定義上、ツールや他のデータソースと相互作用するLLMです。そのタイプの相互作用を促進するためのシステムが常にLLMの周りに存在します。証拠が必要ですか?Claude Codeのソースコードがリークされたとき、51万2,000行のコードがありました。そのコードがハーネスです。世界最高のモデルのメーカーでさえ、ハーネスに多大な投資をしています。
OpenAIとAnthropicのAPIにウェブ検索などが組み込まれている場合—それらは「モデルの一部」ではありません。むしろ、APIの後ろにある軽量なハーネスの一部であり、ツール呼び出しを通じてモデルとそれらのウェブ検索APIをオーケストレートします。
## ハーネスはメモリと結びついている
Sarah Woodersは「メモリはプラグインではない(ハーネスだ)」という素晴らしいブログを書いており、私も完全に同意します。
メモリが特定のハーネスとは別の独立したサービスであるという意見があることがあります。現時点では、これは正しくありません。
ハーネスの大きな責任はコンテキストと相互作用することです。Sarahが言うように:
「メモリをエージェントハーネスにプラグインしてほしいと頼むのは、車に運転をプラグインしてほしいと頼むようなものです。コンテキストを管理すること、したがってメモリを管理することは、エージェントハーネスのコア能力と責任です。」
メモリはコンテキストの一形態に過ぎません。短期メモリ(会話のメッセージ、大きなツール呼び出しの結果)はハーネスによって処理されます。長期メモリ(セッションをまたいだメモリ)はハーネスによって更新・読み込まれる必要があります。Sarahはハーネスがメモリに結びついている他の多くの方法を列挙しています:
- AGENTS.mdまたはCLAUDE.mdファイルはどのようにコンテキストに読み込まれますか?
- スキルのメタデータはどのようにエージェントに示されますか?(システムプロンプト?システムメッセージ?)
- エージェントは自分自身のシステム指示を変更できますか?
- コンパクション後に何が残り、何が失われますか?
- インタラクションは保存されて照会可能になりますか?
- メモリのメタデータはエージェントにどのように提示されますか?
- 現在の作業ディレクトリはどのように表現されますか?どのくらいのファイルシステム情報が公開されますか?
現在、メモリというコンセプトはその初期段階にあります。メモリにとってはまだ非常に早い段階です。透明に言えば、長期メモリはしばしばMVPの一部でないことがわかります。最初にエージェントを一般的に機能させる必要があり、それからパーソナライゼーションを心配できます。これは、業界として私たちがまだメモリを理解しようとしているということを意味します。よく知られた共通のメモリ抽象化は存在しません。メモリがより知られるようになり、ベストプラクティスを発見するにつれて、別個のメモリシステムが意味をなし始めることは可能です。しかし現時点ではまだそこまで来ていません。現時点では、Sarahが言ったように、「最終的に、ハーネスが一般的にコンテキストと状態を管理する方法がエージェントメモリの基盤です。」
## ハーネスを所有していなければ、メモリを所有していない
ハーネスはメモリと密接に結びついています。
💡クローズドなハーネスを使っている場合、特にAPIの後ろにある場合、あなたはメモリを所有していません。
これはいくつかの方法で現れます。
**軽度に悪い:** ステートフルなAPI(OpenAIのResponses APIやAnthropicのサーバーサイドコンパクションなど)を使っている場合、状態を彼らのサーバーに保存しています。モデルを切り替えて以前のスレッドを再開したい場合—それはもはや可能ではありません。
**悪い:** クローズドなハーネス(Claude Agent SDKのような、オープンソースでないClaude Codeをフードの下で使用)を使っている場合、このハーネスはあなたには不明な方法でメモリと相互作用します。おそらくクライアントサイドにいくつかのアーティファクトを作成します—しかし、それらの形状は何で、ハーネスはそれらをどう使うべきですか?それは不明であり、したがって1つのハーネスから別のハーネスに転送不可能です。
💡しかし最悪なのは別のことです—長期メモリを含むハーネス全体がAPIの後ろにある場合です。
この状況では、長期メモリを含めて、メモリへの所有権や可視性はゼロです。ハーネスを知らない(つまりメモリの使い方を知らない)。しかしさらに悪いことに—メモリさえ所有していません!一部がAPIで公開されているかもしれません、まったく公開されていないかもしれません—それに対してコントロールはありません。
「モデルがどんどんハーネスを吸収する」と言うとき—これが本当に意味することです。これらのメモリ関連の部分がモデルプロバイダーが提供するAPIの後ろに入るということです。
💡これは非常に警戒すべきことです—メモリが単一のプラットフォーム、単一のモデルにロックインされることを意味します。
モデルプロバイダーはこれをするための強いインセンティブを持っています。そして彼らは始めています。AnthropicはClaude Managed Agentsを立ち上げました。これはすべてをAPIの後ろに置き、彼らのプラットフォームにロックインします。
ハーネス全体がAPIの後ろになくても、モデルプロバイダーはどんどん多くをAPIの後ろに移動させるインセンティブを持っており、すでにそうしています。例えば:CodexはオープンソースですがOpenAIのエコシステム外では使用できない暗号化されたコンパクションサマリーを生成します。
なぜそうするのですか?メモリは重要であり、モデルだけからは得られないロックインを生み出すからです。
## メモリは重要であり、ロックインを生み出す
メモリはまだ初期段階ですが、それが重要であることは誰もが明らかに理解しています。ユーザーが相互作用するにつれてエージェントが良くなることを可能にし、データフライホイールを構築できるようにします。エージェントを各ユーザーにパーソナライズし、彼らの欲求と使用パターンに合わせて成形するエージェント体験を構築することを可能にします。
💡メモリがなければ、あなたのエージェントは同じツールへのアクセスを持つ誰でも簡単に複製できます。
メモリがあれば、プロプライエタリなデータセット—ユーザーの相互作用と好みのデータセット—を構築します。このプロプライエタリなデータセットにより、差別化された、ますます知的な体験を提供できます。
これまではモデルプロバイダーを切り替えることが比較的簡単でした。同一ではないとしても、類似したAPIを持っています。確かに、プロンプトを少し変える必要がありますが、それほど難しくはありません。
しかしこれはすべてステートレスだからです。
状態が関連付けられた瞬間、切り替えはずっと難しくなります。このメモリが重要だからです。切り替えると、それへのアクセスを失います。
一つのストーリーをお話しします。私は内部でメールアシスタントを持っています。Fleetで構築したテンプレートの上に作られています—Fleetはエンタープライズ対応のOpenClawを構築するためのノーコードプラットフォームです。このプラットフォームにはメモリが組み込まれているので、過去数ヶ月間メールアシスタントと相互作用するにつれてメモリが構築されました。数週間前、エージェントが誤って削除されました。私はとても腹が立ちました!同じテンプレートからエージェントを作成しようとしましたが、体験がずっと悪くなりました。私のすべての好み、トーン、すべてを再び教える必要がありました。
メールエージェントが削除された良い面—メモリがいかに強力で粘着性があるかを気づかせてくれました。
## オープンメモリ、オープンハーネス
メモリはオープンにされる必要があり、エージェント体験を開発している人が所有する必要があります。実際にコントロールするプロプライエタリなデータセットを構築できるようにします。
メモリ(したがってハーネス)はモデルプロバイダーとは別であるべきです。自分のユースケースに最適なモデルを試す選択肢を持ちたいはずです。モデルプロバイダーはメモリを通じてロックインを作り出すインセンティブを持っています。
これが私たちがDeep Agentsを構築している理由です。Deep Agentsは:
- オープンソース
- モデル非依存
- agents.mdやスキルのようなオープンスタンダードを使用
- メモリ保存のためのMongo、Postgres、Redis、その他へのプラグイン
- デプロイ可能:(1) LangSmith Deployment経由(セルフホスト可能、任意のクラウドにデプロイ可能、メモリストアとして機能する独自のデータベースを持ち込める);(2) 任意の標準ウェブホスティングフレームワークの後ろ
メモリを所有するためには、オープンハーネスを使用する必要があります。
今日Deep Agentsを試してみてください。
レビューと考えをいただいた皆さんに感謝:
- Sydney Runkle、Deep Agentsとメモリの素晴らしい作業をしています
- Viv Trivedy、エージェントハーネスの第一人者
- Nuno Campos、ファイナンスエージェントのコンテキストエンジニアリングについての素晴らしい記事があります
- Sarah Wooders、ステートフルエージェントの最前線に一貫していたLettaのCTO
harness-designagent-opsai-thinkingmemorylangchain
あなたのハーネス、あなたのメモリ — エージェントハーネスとメモリの密接な関係
♥ 635↻ 75
原文を表示 / Show original
Agent harnesses are becoming the dominant way to build agents, and they are not going anywhere. These harnesses are intimately tied to agent memory. If you used a closed harness - especially if it’s behind a proprietary API - you are choosing to yield control of your agent’s memory to a third party. Memory is incredibly important to creating good and sticky agentic experiences. This creates incredible lock in. Memory - and therefor harnesses - should be open, so that you own your own memory
Agent Harnesses are how you build agents, and they’re not going anywhere
The “best” way to build agentic systems has changed dramatically over the past three years. When ChatGPT came out, all you could do were simple RAG chains (LangChain). Then the models got a little better, and could create more complex flows (LangGraph). Then they got a lot better, and that gave rise to a new type of scaffolding - agent harnesses.
Examples of agent harnesses include Claude Code, Deep Agents, Pi (powers OpenClaw), OpenCode, Codex, Letta Code, and many more.
💡Agent harnesses are not going away.
There is sometimes sentiment that models will absorb more and more of the scaffolding. This is not true. What has happened (and will continue to happen) is that a lot of the scaffolding needed in 2023 is no longer needed. But this has been replaced by other types of scaffolding. An agent, by definition, is an LLM interacting with tools and other sources of data. There will always be a system around the LLM to facilitate that type of interaction. Need evidence? When Claude Code’s source code was leaked, there was 512k lines of code. That code is the harness. Even the makers of the best model in the world are investing heavily in harnesses.
When things like web search are built into OpenAI and Anthropic’s APIs - they are not “part of the model”. Rather, they are part of a lightweight harness that sits behind their APIs and orchestrates the model with those web search APIs (via nothing other than tool calling).
Harnesses are tied to memory
Sarah Wooders wrote a great blog on why “memory isn’t a plugin (it’s the harness)”, and I couldn’t agree with it more.
Sarah Wooders
@sarahwooders
·
Apr 4
Article
Why memory isn't a plugin (it's the harness)
Ever since we've been working on MemGPT (now @Letta_AI), a common question @charlespacker and I have gotten is:
"how can I plug your memory system into my agent?"
To me, this question doesn't make...
14
90
540
128K
There is sometimes sentiment that memory is a standalone service, separate from any particular harness. At this point in time, that is not true.
A large responsibility of the harness is to interact with context. As Sarah puts it:
Asking to plug memory into an agent harness is like asking to plug driving into a car. Managing context, and therefore memory, is a core capability and responsibility of the agent harness.
Memory is just a form of context. Short term memory (messages in the conversation, large tool call results) are handled by the harness. Long term memory (cross session memory) needs to be updated and read by the harness. Sarah lists out many other ways the harness is tied to memory:
How is the AGENTS.md or CLAUDE.md file loaded into context?
How is skill metadata shown to the agents? (in the system prompt? in system messages?)
Can the agent modify its own system instructions?
What survives compaction, and what's lost?
Are interactions stored and made queryable?
How is memory metadata presented to the agent?
How is the current working directory represented? How much filesystem information is exposed?
Right now, memory as a concept is in it’s infancy. It’s so early for memory. Transparently, we see that long term memory is often not part of the MVP. First you need to get an agent working generally, then you can worry about personalization. This means that we (as an industry) are still figuring out memory. This means there are not well known or common abstractions for memory. If memory does become more known, and as we discover best practices, it is possible that separate memory systems start to make sense. But not at this point in time. Right now, as Sarah said, “ultimately, how the harness manages context and state in general is the foundation for agent memory.”
if you don't own your harness, you don't own your memory
The harness is intimately tied to memory.
💡If you use a closed harness, especially if its behind an API, you don’t own your memory.
This manifests itself in several ways.
Mildly bad: If you use a stateful API (like OpenAI’s Responses API, or Anthropic’s server side compaction), you are storing state on their server. If you want to swap models and resume previous threads - that is no longer doable.
Bad: If you use a closed harness (like Claude Agent SDK, which uses Claude Code under the hood, which is not open source), this harness interacts with memory in a way that is unknown to you. Maybe it creates some artifacts client side - but what is the shape of those, and how should a harness use those? That is unknown, and therefor non-transferrable from one harness to another.
💡But worst is something else - when the whole harness, including long term memory is behind an API.
In this situation, you have zero ownership or visibility into memory, including long term memory. You do not know the harness (which means you don’t know how to use the memory). But even worse - you don’t even own the memory! Maybe some parts are exposed via API, maybe no parts are - you have no control over that.
When people say that the “models will absorb more and more of the harness” - this is what they really mean. They mean that these memory related parts will go behind the APIs that model providers offer.
💡This is incredibly alarming - it means that memory will become locked into a single platform, a single model.
Model providers are incredibly incentivized to do this. And they are starting to. Anthropic launched Claude Managed Agents. This puts literally everything behind an API, locked into their platform.
Even if the whole harness isn’t behind the API, model providers are incentivized to move more and more behind APIs - and are already doing so. For example: even though Codex is an open source, it generates an encrypted compaction summary (that is not usable outside of the OpenAI ecosystem).
Why are they doing this? Because memory is important, and it creates lock in that they don’t get from just the model.
Memory is important, and it creates lock in
Although memory is early, it is clear to everyone that it is important. It is what allows agents to get better as users interact with them, and allows you build up a data flywheel. It is what allows your agent to be personalized to each of your users, and build up an agentic experience that molds to their desires and usage patterns.
💡Without memory, your agents are easily replicable by anyone who has access to the same tools.
With memory, you build up a proprietary dataset - a dataset of user interactions and preferences. This proprietary dataset allows you to provide a differentiated and increasingly intelligent experience.
It’s been relatively easy to switch model providers to date. They have similar, if not identical, APIs. Sure, you have to change prompts a little bit, but that’s not that hard.
But this is all because they are stateless.
As soon as there is any state associated, its much harder to switch. Because this memory matters. And if you switch, you lose access to it.
Let me tell a story. I have an email assistant internally. It’s built on top of a template in Fleet, our no-code platform for building Enterprise ready OpenClaws. This platform has memory built in, so as I interacted with my email assistant over the past few months it built up memory. A few weeks ago, my agent got deleted by accident. I was pissed! I tried to create an agent from the same template - but the experience was so much worse. I had to reteach it all my preferences, my tone, everything.
The plus side of my email agent deleted - it made me realize how powerful and sticky memory could be.
Open Memory, Open Harnesses
Memory needs to be opened, owned by whomever is developing the agentic experience. It allows you to build up a proprietary dataset that you actually control.
Memory (and therefor harnesses) should be separate from model providers. You should want optionality to try out whatever models are best for your use case. Model providers are incentivized to create lock in via memory.
This is why we are building Deep Agents. Deep Agents:
Is open source
Is model agnostic
Uses open standards like agents.md and skills
Has plugins to Mongo, Postgres, Redis and others for storing memories
Is deployable: (1) via LangSmith Deployment (self hostable, can be deployed on any cloud, can bring your own database to serve as a memory store); (2) behind any standard web hosting framework
In order to own your memory, you need to be using an Open Harness
Try out Deep Agents today.
Thank you to a few people for review and thoughts:
Sydney Runkle, who is doing a lot of great Deep Agents and memory work
Viv Trivedy, who is a leading voice on agent harnesses
Nuno Campos, who has some great writing on context engineering for finance agents
Sarah Wooders, who is CTO of Letta, a company that has consistently been at the forefront of stateful agents