記事一覧へ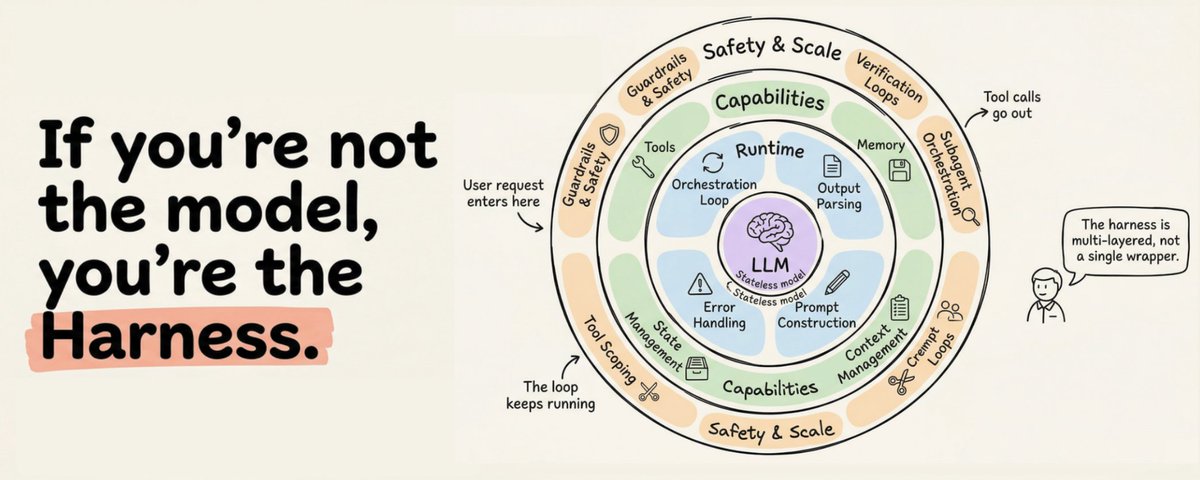
Anthropic、OpenAI、Perplexity、LangChainが実際に構築しているものへの深掘り。オーケストレーションループ、ツール、メモリ、コンテキスト管理、そしてステートレスなLLMを有能なエージェントに変換する他のすべてをカバーします。
あなたはチャットボットを構築しました。おそらくいくつかのツールでReActループを接続しました。デモでは機能します。そして本番環境で構築しようとすると、車輪が外れます:モデルは3ステップ前にしたことを忘れ、ツール呼び出しはサイレントに失敗し、コンテキストウィンドウはゴミで埋まります。
問題はモデルではありません。モデルの周りにあるすべてのものです。
LangChainはこれを証明しました。LLMをラップするインフラだけを変更したとき(同じモデル、同じ重み)、TerminalBench 2.0でトップ30外からランク5にジャンプしました。別のリサーチプロジェクトは、LLMがインフラ自体を最適化することで76.4%のパス率を達成し、手作業で設計されたシステムを上回りました。
そのインフラには今や名前があります:エージェントハーネスです。
## エージェントハーネスとは何か
この用語は2026年初頭に正式化されましたが、コンセプトはずっと前から存在していました。ハーネスはLLMをラップする完全なソフトウェアインフラです:オーケストレーションループ、ツール、メモリ、コンテキスト管理、状態の永続化、エラーハンドリング、ガードレール。AnthropicのClaude Codeドキュメントは簡潔に述べています:SDKは「Claude Codeを動かすエージェントハーネス」です。OpenAIのCodexチームは同じフレーミングを使用し、「エージェント」と「ハーネス」という用語をLLMを有用にする非モデルインフラを指すものとして明示的に等置しています。
LangChainのVivek Triveryによる標準的な公式が気に入っています:「モデルでなければ、ハーネスだ。」
ここで人々が混乱するポイントがあります。「エージェント」は創発的な行動です:ユーザーが相互作用する目標指向の、ツールを使用する、自己修正するエンティティ。ハーネスはその行動を生み出す機械装置です。誰かが「エージェントを構築した」と言うとき、ハーネスを構築してモデルに向けたということを意味します。
Beren Millidge は2023年のエッセイ「自然言語コンピュータとしてのスキャフォールドされたLLM」でこの類比を正確にしました。生のLLMはRAMなし、ディスクなし、I/Oなしのコアです。コンテキストウィンドウはRAMとして機能します(速いが制限がある)。外部データベースはディスクストレージとして機能します(大きいが遅い)。ツール統合はデバイスドライバとして機能します。ハーネスはオペレーティングシステムです。Millidgeが書いたように:「私たちはフォン・ノイマンアーキテクチャを再発明しました」—なぜならそれはあらゆるコンピューティングシステムにとって自然な抽象化だからです。
## エンジニアリングの3つのレベル
モデルを囲む3つの同心円状のエンジニアリングレベル:
1. **プロンプトエンジニアリング**:モデルが受け取る指示を作成する
2. **コンテキストエンジニアリング**:モデルが何を見て、いつ見るかを管理する
3. **ハーネスエンジニアリング**:上記の両方に加え、完全なアプリケーションインフラ(ツールオーケストレーション、状態の永続化、エラーリカバリー、検証ループ、安全性の強制、ライフサイクル管理)を包含する
ハーネスはプロンプトのラッパーではありません。自律エージェントの行動を可能にする完全なシステムです。
## 本番ハーネスの12のコンポーネント
Anthropic、OpenAI、LangChain、より広い実践者コミュニティを総合すると、本番エージェントハーネスには12の異なるコンポーネントがあります。一つずつ見ていきましょう。
### 1. オーケストレーションループ
これがハートビートです。Thought-Action-Observation(TAO)サイクル(ReActループとも呼ばれる)を実装します。ループは:プロンプトをアセンブルし、LLMを呼び出し、出力を解析し、ツール呼び出しを実行し、結果をフィードバックし、完了するまで繰り返します。
機械的には、しばしばwhileループに過ぎません。複雑さはループが管理するすべてのものにあり、ループ自体ではありません。Anthropicはランタイムを「ダムループ」と説明しています—すべてのインテリジェンスはモデルにある。ハーネスはターンを管理するだけです。
### 2. ツール
ツールはエージェントの手です。LLMのコンテキストに注入されるスキーマ(名前、説明、パラメータタイプ)として定義されることで、モデルは何が利用可能かを知ります。ツール層は登録、スキーマ検証、引数の抽出、サンドボックス実行、結果のキャプチャ、LLM読み取り可能な観察への結果のフォーマットを処理します。
Claude Codeは6つのカテゴリにわたってツールを提供します:ファイル操作、検索、実行、ウェブアクセス、コードインテリジェンス、サブエージェントのスポーニング。OpenAIのAgents SDKはファンクションツール(@function_tool経由)、ホスティングツール(WebSearch、CodeInterpreter、FileSearch)、MCPサーバーツールをサポートします。
### 3. メモリ
メモリは複数の時間スケールで動作します。短期メモリは単一セッション内の会話履歴です。長期メモリはセッションをまたいで持続します:AnthropicはCLAUDE.mdプロジェクトファイルと自動生成されるMEMORY.mdファイルを使用します;LangGraphは名前空間で整理されたJSON Storeを使用します;OpenAIはSQLiteまたはRedisでバックアップされたセッションをサポートします。
Claude Codeは3層の階層を実装します:軽量なインデックス(エントリごとに約150文字、常に読み込まれる)、オンデマンドで取り込まれる詳細なトピックファイル、検索経由でのみアクセスされる生のトランスクリプト。重要な設計原則:エージェントは自分自身のメモリを「ヒント」として扱い、行動する前に実際の状態に対して検証します。
### 4. コンテキスト管理
ここで多くのエージェントがサイレントに失敗します。コアの問題はコンテキストの腐敗です:キーコンテンツがウィンドウの中間位置にある場合、モデルのパフォーマンスは30%以上低下します(Chromaリサーチ、Stanfordの「Lost in the Middle」の発見によって裏付けられています)。100万トークンウィンドウでさえ、コンテキストが増えるにつれて指示に従う能力の低下に苦しみます。
本番の戦略には:
- **コンパクション**:制限に近づくときに会話履歴を要約する(Claude Codeはアーキテクチャの決定と未解決のバグを保持し、冗長なツール出力を破棄する)
- **観察マスキング**:JetBrainsのJunieは古いツール出力を隠しながらツール呼び出しを可視のままにする
- **ジャストインタイム取得**:軽量な識別子を維持してデータを動的に読み込む(Claude Codeはファイル全体を読み込む代わりにgrep、glob、head、tailを使用する)
- **サブエージェントの委任**:各サブエージェントは広範に探索するが、1,000〜2,000トークンの凝縮されたサマリーのみを返す
Anthropicのコンテキストエンジニアリングガイドが目標を述べています:望む結果の可能性を最大化する最小の高シグナルトークンセットを見つけること。
### 5. プロンプト構成
これは各ステップでモデルが実際に見るものをアセンブルします。階層的です:システムプロンプト、ツール定義、メモリファイル、会話履歴、現在のユーザーメッセージ。
OpenAIのCodexは厳格な優先スタックを使用します:サーバー制御のシステムメッセージ(最高優先度)、ツール定義、開発者指示、ユーザー指示(カスケードされるAGENTS.mdファイル、32 KiBの制限)、会話履歴。
### 6. 出力解析
現代のハーネスはネイティブのツール呼び出しに依存しています。モデルが解析が必要なフリーテキストではなく構造化されたtool_callsオブジェクトを返すようにします。ハーネスは確認します:ツール呼び出しはありますか?実行してループ。ツール呼び出しなし?それが最終的な答えです。
構造化された出力については、OpenAIとLangChainの両方がPydanticモデルによるスキーマ制約の応答をサポートします。RetryWithErrorOutputParser(元のプロンプト、失敗した完了、解析エラーをモデルにフィードバックする)のようなレガシーアプローチはエッジケースのために引き続き利用可能です。
### 7. 状態管理
LangGraphはグラフノードを流れる型付き辞書として状態をモデル化し、レデューサーが更新をマージします。チェックポイントはスーパーステップの境界で発生し、中断後の再開とタイムトラベルデバッグを可能にします。OpenAIは4つの相互排他的な戦略を提供します:アプリケーションメモリ、SDKセッション、サーバーサイドConversations API、または軽量なprevious_response_idチェーン。Claude Codeは異なるアプローチを取ります:チェックポイントとしてのgitコミットと構造化されたスクラッチパッドとしてのプログレスファイル。
### 8. エラーハンドリング
なぜこれが重要か:ステップあたり99%の成功率を持つ10ステップのプロセスでも、エンドツーエンドの成功率は約90.4%に過ぎません。エラーは急速に複合します。
LangGraphは4つのエラータイプを区別します:一時的(バックオフ付きで再試行)、LLM回復可能(モデルが調整できるようにToolMessageとしてエラーを返す)、ユーザー修正可能(人間の入力のために中断する)、予期しない(デバッグのためにバブルアップ)。Anthropicはループを実行し続けるためにツールハンドラー内でエラーをキャッチしてエラー結果として返します。Stripeの本番ハーネスは再試行回数を2回に制限します。
### 9. ガードレールと安全性
OpenAIのSDKは3つのレベルを実装します:入力ガードレール(最初のエージェントで実行)、出力ガードレール(最終出力で実行)、ツールガードレール(すべてのツール呼び出しで実行)。「トリップワイヤー」メカニズムがトリガーされたときにエージェントを即座に停止させます。
Anthropicは権限の強制をモデルの推論からアーキテクチャ的に分離します。モデルは何を試みるかを決定します;ツールシステムが何が許可されるかを決定します。Claude Codeは約40の個別のツール能力を独立してゲートし、3つのステージがあります:プロジェクトロード時の信頼確立、各ツール呼び出しの前の権限チェック、高リスクな操作の明示的なユーザー確認。
### 10. 検証ループ
これがおもちゃのデモと本番エージェントを分けるものです。Anthropicは3つのアプローチを推奨します:ルールベースのフィードバック(テスト、リンター、型チェッカー)、ビジュアルフィードバック(UIタスクのPlaywright経由のスクリーンショット)、LLMをジャッジとして使う(別のサブエージェントが出力を評価する)。
Claude Codeの作者Boris Chernyは、モデルに自分の作業を検証する方法を与えることで品質が2〜3倍向上すると述べています。
### 11. サブエージェントのオーケストレーション
Claude Codeは3つの実行モデルをサポートします:Fork(親コンテキストのバイト同一コピー)、Teammate(ファイルベースのメールボックス通信を持つ別のターミナルペイン)、Worktree(独自のgit worktree、エージェントごとの独立したブランチ)。OpenAIのSDKはagents-as-tools(スペシャリストが限定されたサブタスクを処理)とhandoffs(スペシャリストが完全なコントロールを引き継ぐ)をサポートします。LangGraphはサブエージェントをネストされた状態グラフとして実装します。
## 動作中のループ:ステップバイステップのウォークスルー
コンポーネントを理解したので、単一のサイクルでそれらがどのように連携するかをたどってみましょう。
**ステップ1(プロンプトアセンブリ):** ハーネスが完全な入力を構築します:システムプロンプト + ツールスキーマ + メモリファイル + 会話履歴 + 現在のユーザーメッセージ。重要なコンテキストはプロンプトの最初と最後に配置されます(「Lost in the Middle」の発見)。
**ステップ2(LLM推論):** アセンブルされたプロンプトがモデルAPIに送られます。モデルが出力トークンを生成します:テキスト、ツール呼び出しリクエスト、またはその両方。
**ステップ3(出力分類):** モデルがツール呼び出しなしのテキストを生成した場合、ループは終わります。ツール呼び出しをリクエストした場合、実行に進みます。ハンドオフがリクエストされた場合、現在のエージェントを更新して再起動します。
**ステップ4(ツール実行):** 各ツール呼び出しに対して、ハーネスは引数を検証し、権限を確認し、サンドボックス環境で実行し、結果をキャプチャします。読み取り専用の操作は並行して実行できます;変更を加える操作はシリアルで実行されます。
**ステップ5(結果のパッケージング):** ツールの結果はLLM読み取り可能なメッセージとしてフォーマットされます。エラーはキャッチされ、モデルが自己修正できるようにエラー結果として返されます。
**ステップ6(コンテキスト更新):** 結果が会話履歴に追加されます。コンテキストウィンドウの制限に近づいている場合、ハーネスはコンパクションをトリガーします。
**ステップ7(ループ):** ステップ1に戻ります。終了するまで繰り返します。
終了条件は階層化されています:モデルがツール呼び出しなしの応答を生成する、最大ターン制限を超える、トークン予算が尽きる、ガードレールのトリップワイヤーが発火する、ユーザーが中断する、安全上の拒否が返される。シンプルな質問は1〜2ターンかかるかもしれません。複雑なリファクタリングタスクは多くのターンにわたって数十のツール呼び出しを連鎖させることができます。
複数のコンテキストウィンドウにわたる長時間実行タスクのために、Anthropicは2フェーズの「Ralphループ」パターンを開発しました:Initializerエージェントが環境をセットアップし(initスクリプト、プログレスファイル、機能リスト、初期gitコミット)、その後のすべてのセッションでCodingエージェントがgitログとプログレスファイルを読んで自分を方向付け、最高優先度の未完成機能を選んで作業し、コミットし、サマリーを書きます。ファイルシステムがコンテキストウィンドウをまたいで継続性を提供します。
## 実際のフレームワークがパターンをどう実装するか
AnthropicのClaude Agent SDKは、エージェントループを作成してメッセージをストリーミングする非同期イテレータを返す単一のquery()関数を通じてハーネスを公開します。ランタイムは「ダムループ」です。すべてのインテリジェンスはモデルにあります。Claude Codeはギャザー・アクト・ベリファイサイクルを使用します:コンテキストを収集し(ファイルを検索、コードを読む)、アクションを取り(ファイルを編集、コマンドを実行)、結果を検証し(テストを実行、出力を確認)、繰り返します。
OpenAIのAgents SDKは3つのモードを持つRunnerクラスを通じてハーネスを実装します:非同期、同期、ストリーム。SDKは「コードファースト」です:ワークフローロジックはグラフDSLではなくネイティブのPythonで表現されます。Codexハーネスはこれを3層アーキテクチャで拡張します:Codex Core(エージェントコード + ランタイム)、App Server(双方向JSON-RPC API)、クライアントサーフェス(CLI、VS Code、ウェブアプリ)。すべてのサーフェスが同じハーネスを共有します。これが「Codexモデルが汎用チャットウィンドウよりもCodexサーフェスでより良く感じる」理由です。
LangGraphはハーネスを明示的な状態グラフとしてモデル化します。2つのノード(llm_callとtool_node)が条件付きエッジで接続されています:ツール呼び出しが存在する場合、tool_nodeにルーティング;存在しない場合、ENDにルーティング。LangGraphはLangChainのAgentExecutorから進化しました。AgentExecutorはv0.2で非推奨になりました—拡張が難しく、マルチエージェントサポートがなかったためです。LangChainのDeep Agentsは「エージェントハーネス」という用語を明示的に使用します:組み込みツール、計画(write_todosツール)、コンテキスト管理のためのファイルシステム、サブエージェントのスポーニング、永続的なメモリ。
CrewAIはロールベースのマルチエージェントアーキテクチャを実装します:Agent(LLMの周りのハーネス、役割、目標、バックグラウンド、ツールで定義)、Task(作業の単位)、Crew(エージェントのコレクション)。CrewAIのFlows層は「インテリジェンスが重要な場所に確定的なバックボーン」を追加し、ルーティングと検証を管理しながらCrewsが自律的なコラボレーションを処理します。
AutoGen(Microsoft Agent Frameworkに進化中)は会話駆動のオーケストレーションを先駆けました。3層アーキテクチャ(Core、AgentChat、Extensions)は5つのオーケストレーションパターンをサポートします:シーケンシャル、コンカレント(ファンアウト/ファンイン)、グループチャット、ハンドオフ、マグネティック(マネージャーエージェントがスペシャリストを調整する動的タスク台帳を維持)。
## スキャフォールドのメタファー
スキャフォールドのメタファーは装飾的ではありません。正確です。建設の足場は、そうでなければ届かない構造を労働者が構築できるようにする一時的なインフラです。建設はしません。しかしそれなしでは、労働者は上の階に届けません。
重要な洞察:足場は建物が完成したときに取り除かれます。モデルが改善されるにつれて、ハーネスの複雑さは減少するはずです。Manusは6ヶ月で5回再構築され、各書き直しで複雑さが取り除かれました。複雑なツール定義が一般的なシェル実行になりました。「管理エージェント」がシンプルな構造化ハンドオフになりました。
これは共進化の原則を指し示しています:モデルは今や特定のハーネスをループに持ってトレーニング後に調整されています。Claude Codeのモデルはトレーニングされた特定のハーネスを使うことを学びました。ツール実装を変えると、この密結合のためにパフォーマンスが低下することがあります。
ハーネス設計の「将来性テスト」:より強力なモデルでパフォーマンスがハーネスの複雑さを追加せずにスケールアップする場合、設計は健全です。
## すべてのハーネスを定義する7つの決定
すべてのハーネスアーキテクトは7つの選択に直面します:
**1. シングルエージェント対マルチエージェント。** AnthropicとOpenAIの両方が言います:まず単一エージェントを最大化する。マルチエージェントシステムはオーバーヘッドを追加します(ルーティングのための余分なLLM呼び出し、ハンドオフ時のコンテキスト損失)。ツールの過負荷が約10の重複するツールを超えるか、明確に別々のタスクドメインが存在する場合のみ分割する。
**2. ReAct対計画-実行。** ReActは各ステップで推論とアクションを交互に行います(柔軟だがステップあたりのコストが高い)。計画-実行は計画と実行を分離します。LLMCompilerは逐次ReActより3.6倍の高速化を報告しています。
**3. コンテキストウィンドウ管理戦略。** 5つの本番アプローチ:時間ベースのクリア、会話の要約、観察マスキング、構造化されたメモ取り、サブエージェントの委任。ACONリサーチは推論トレースを生のツール出力よりも優先することで、95%以上の精度を保ちながら26〜54%のトークン削減を示しました。
**4. 検証ループの設計。** 計算検証(テスト、リンター)は確定的なグラウンドトゥルースを提供します。推論的検証(LLMをジャッジとして)はセマンティックな問題をキャッチしますがレイテンシが増加します。Martin FowlerのThoughtworksチームはこれをガイド(フィードフォワード、アクションの前に方向付け)対センサー(フィードバック、アクションの後に観察)としてフレーミングします。
**5. 権限と安全性のアーキテクチャ。** 許容的(速いが危険、ほとんどのアクションを自動承認)対制限的(安全だが遅い、各アクションに承認が必要)。選択はデプロイメントのコンテキストに依存します。
**6. ツールスコーピング戦略。** ツールが多いほど、しばしばパフォーマンスが悪くなります。Vercelはv0から80%のツールを削除してより良い結果を得ました。Claude Codeは遅延ロードで95%のコンテキスト削減を達成します。原則:現在のステップに必要な最小ツールセットを公開する。
**7. ハーネスの厚さ。** どれだけのロジックがハーネスにあり、どれだけがモデルにあるか。Anthropicは薄いハーネスとモデルの改善に賭けています。グラフベースのフレームワークは明示的なコントロールに賭けています。Anthropicは新しいモデルバージョンがその能力を内面化するにつれて、定期的にClaude Codeのハーネスから計画ステップを削除します。
## ハーネスが製品だ
同一のモデルを使用する2つの製品は、ハーネス設計だけに基づいて劇的に異なるパフォーマンスを示すことがあります。TerminalBenchの証拠は明確です:ハーネスだけを変えることでエージェントのランキングが20以上ポジション移動しました。
ハーネスは解決済みの問題でも汎用品の層でもありません。困難なエンジニアリングが住む場所です:コンテキストを希少なリソースとして管理し、複合する前に失敗をキャッチする検証ループを設計し、幻覚なしに継続性を提供するメモリシステムを構築し、どれだけのスキャフォールディングを構築するか対どれだけをモデルに任せるかについてアーキテクチャ上の賭けをする。
このフィールドはモデルが改善されるにつれて薄いハーネスに向かっています。しかしハーネス自体はなくなりません。最も有能なモデルでさえ、コンテキストウィンドウを管理し、ツール呼び出しを実行し、状態を永続化し、作業を検証するための何かが必要です。
次にエージェントが失敗したとき、モデルを責めないでください。ハーネスを見てください。
以上です!
楽しんでいただけたら:
私を見つけてください → @akshay_pachaar ✔️
毎日、AI、機械学習、バイブコーディングのベストプラクティスに関するチュートリアルとインサイトを共有しています。
harness-designagent-opsai-thinkingorchestrationmemory
エージェントハーネスの解剖学 — Anthropic/OpenAI/LangChainが実際に作っているもの
♥ 1,083↻ 148
原文を表示 / Show original
A deep dive into what Anthropic, OpenAI, Perplexity and LangChain are actually building. Covering the orchestration loop, tools, memory, context management, and everything else that transforms a stateless LLM into a capable agent.
You've built a chatbot. Maybe you've wired up a ReAct loop with a few tools. It works for demos. Then you try to build something production-grade, and the wheels come off: the model forgets what it did three steps ago, tool calls fail silently, and context windows fill up with garbage.
The problem isn't your model. It's everything around your model.
LangChain proved this when they changed only the infrastructure wrapping their LLM (same model, same weights) and jumped from outside the top 30 to rank 5 on TerminalBench 2.0. A separate research project hit a 76.4% pass rate by having an LLM optimize the infrastructure itself, surpassing hand-designed systems.
That infrastructure has a name now: the agent harness.
What Is the Agent Harness?
The term was formalized in early 2026, but the concept existed long before. The harness is the complete software infrastructure wrapping an LLM: orchestration loop, tools, memory, context management, state persistence, error handling, and guardrails. Anthropic's Claude Code documentation puts it simply: the SDK is "the agent harness that powers Claude Code." OpenAI's Codex team uses the same framing, explicitly equating the terms "agent" and "harness" to refer to the non-model infrastructure that makes the LLM useful.
I really liked the canonical formula, from LangChain's Vivek Trivedy: "If you're not the model, you're the harness."
Here's the distinction that trips people up. The "agent" is the emergent behavior: the goal-directed, tool-using, self-correcting entity the user interacts with. The harness is the machinery producing that behavior. When someone says "I built an agent," they mean they built a harness and pointed it at a model.
Beren Millidge made this analogy precise in his 2023 essay "Scaffolded LLMs as Natural Language Computers." A raw LLM is a CPU with no RAM, no disk, and no I/O. The context window serves as RAM (fast but limited). External databases function as disk storage (large but slow). Tool integrations act as device drivers. The harness is the operating system. As Millidge wrote: "We have reinvented the Von Neumann architecture" because it's a natural abstraction for any computing system.
Three Levels of Engineering
Three concentric levels of engineering surround the model:
Prompt engineering crafts the instructions the model receives.
Context engineering manages what the model sees and when.
Harness engineering encompasses both, plus the entire application infrastructure: tool orchestration, state persistence, error recovery, verification loops, safety enforcement, and lifecycle management.
The harness is not a wrapper around a prompt. It is the complete system that makes autonomous agent behavior possible.
The 12 Components of a Production Harness
Synthesizing across Anthropic, OpenAI, LangChain, and the broader practitioner community, a production agent harness has twelve distinct components. Let's walk through each one.
1. The Orchestration Loop
This is the heartbeat. It implements the Thought-Action-Observation (TAO) cycle, also called the ReAct loop. The loop runs: assemble prompt, call LLM, parse output, execute any tool calls, feed results back, repeat until done.
Mechanically, it's often just a while loop. The complexity lives in everything the loop manages, not the loop itself. Anthropic describes their runtime as a "dumb loop" where all intelligence lives in the model. The harness just manages turns.
2. Tools
Tools are the agent's hands. They're defined as schemas (name, description, parameter types) injected into the LLM's context so the model knows what's available. The tool layer handles registration, schema validation, argument extraction, sandboxed execution, result capture, and formatting results back into LLM-readable observations.
Claude Code provides tools across six categories: file operations, search, execution, web access, code intelligence, and subagent spawning. OpenAI's Agents SDK supports function tools (via @function_tool), hosted tools (WebSearch, CodeInterpreter, FileSearch), and MCP server tools.
3. Memory
Memory operates at multiple timescales. Short-term memory is conversation history within a single session. Long-term memory persists across sessions: Anthropic uses CLAUDE.md project files and auto-generated MEMORY.md files; LangGraph uses namespace-organized JSON Stores; OpenAI supports Sessions backed by SQLite or Redis.
Claude Code implements a three-tier hierarchy: a lightweight index (~150 characters per entry, always loaded), detailed topic files pulled in on demand, and raw transcripts accessed via search only. A critical design principle: the agent treats its own memory as a "hint" and verifies against actual state before acting.
4. Context Management
This is where many agents fail silently. The core problem is context rot: model performance degrades 30%+ when key content falls in mid-window positions (Chroma research, corroborated by Stanford's "Lost in the Middle" finding). Even million-token windows suffer from instruction-following degradation as context grows.
Production strategies include:
Compaction: summarizing conversation history when approaching limits (Claude Code preserves architectural decisions and unresolved bugs while discarding redundant tool outputs)
Observation masking: JetBrains' Junie hides old tool outputs while keeping tool calls visible
Just-in-time retrieval: maintaining lightweight identifiers and loading data dynamically (Claude Code uses grep, glob, head, tail rather than loading full files)
Sub-agent delegation: each subagent explores extensively but returns only 1,000 to 2,000 token condensed summaries
Anthropic's context engineering guide states the goal: find the smallest possible set of high-signal tokens that maximize likelihood of the desired outcome.
5. Prompt Construction
This assembles what the model actually sees at each step. It's hierarchical: system prompt, tool definitions, memory files, conversation history, and the current user message.
OpenAI's Codex uses a strict priority stack: server-controlled system message (highest priority), tool definitions, developer instructions, user instructions (cascading AGENTS.md files, 32 KiB limit), then conversation history.
6. Output Parsing
Modern harnesses rely on native tool calling, where the model returns structured tool_calls objects rather than free-text that must be parsed. The harness checks: are there tool calls? Execute them and loop. No tool calls? That's the final answer.
For structured outputs, both OpenAI and LangChain support schema-constrained responses via Pydantic models. Legacy approaches like RetryWithErrorOutputParser (which feeds the original prompt, the failed completion, and the parsing error back to the model) remain available for edge cases.
7. State Management
LangGraph models state as typed dictionaries flowing through graph nodes, with reducers merging updates. Checkpointing happens at super-step boundaries, enabling resume after interruptions and time-travel debugging. OpenAI offers four mutually exclusive strategies: application memory, SDK sessions, server-side Conversations API, or lightweight previous_response_id chaining. Claude Code takes a different approach: git commits as checkpoints and progress files as structured scratchpads.
8. Error Handling
Here's why this matters: a 10-step process with 99% per-step success still has only ~90.4% end-to-end success. Errors compound fast.
LangGraph distinguishes four error types: transient (retry with backoff), LLM-recoverable (return error as ToolMessage so the model can adjust), user-fixable (interrupt for human input), and unexpected (bubble up for debugging). Anthropic catches failures within tool handlers and returns them as error results to keep the loop running. Stripe's production harness caps retry attempts at two.
9. Guardrails and Safety
OpenAI's SDK implements three levels: input guardrails (run on first agent), output guardrails (run on final output), and tool guardrails (run on every tool invocation). A "tripwire" mechanism halts the agent immediately when triggered.
Anthropic separates permission enforcement from model reasoning architecturally. The model decides what to attempt; the tool system decides what's allowed. Claude Code gates ~40 discrete tool capabilities independently, with three stages: trust establishment at project load, permission check before each tool call, and explicit user confirmation for high-risk operations.
10. Verification Loops
This is what separates toy demos from production agents. Anthropic recommends three approaches: rules-based feedback (tests, linters, type checkers), visual feedback (screenshots via Playwright for UI tasks), and LLM-as-judge (a separate subagent evaluates output).
Boris Cherny, creator of Claude Code, noted that giving the model a way to verify its work improves quality by 2 to 3x.
11. Subagent Orchestration
Claude Code supports three execution models: Fork (byte-identical copy of parent context), Teammate (separate terminal pane with file-based mailbox communication), and Worktree (own git worktree, isolated branch per agent). OpenAI's SDK supports agents-as-tools (specialist handles bounded subtask) and handoffs (specialist takes full control). LangGraph implements subagents as nested state graphs.
The Loop in Motion: A Step-by-Step Walkthrough
Now that you know the components, let's trace how they work together in a single cycle.
Step 1 (Prompt Assembly): The harness constructs the full input: system prompt + tool schemas + memory files + conversation history + current user message. Important context is positioned at the beginning and end of the prompt (the "Lost in the Middle" finding).
Step 2 (LLM Inference): The assembled prompt goes to the model API. The model generates output tokens: text, tool call requests, or both.
Step 3 (Output Classification): If the model produced text with no tool calls, the loop ends. If it requested tool calls, proceed to execution. If a handoff was requested, update the current agent and restart.
Step 4 (Tool Execution): For each tool call, the harness validates arguments, checks permissions, executes in a sandboxed environment, and captures results. Read-only operations can run concurrently; mutating operations run serially.
Step 5 (Result Packaging): Tool results are formatted as LLM-readable messages. Errors are caught and returned as error results so the model can self-correct.
Step 6 (Context Update): Results are appended to conversation history. If approaching the context window limit, the harness triggers compaction.
Step 7 (Loop): Return to Step 1. Repeat until termination.
Termination conditions are layered: the model produces a response with no tool calls, maximum turn limit is exceeded, token budget is exhausted, a guardrail tripwire fires, the user interrupts, or a safety refusal is returned. A simple question might take 1 to 2 turns. A complex refactoring task can chain dozens of tool calls across many turns.
For long-running tasks spanning multiple context windows, Anthropic developed a two-phase "Ralph Loop" pattern: an Initializer Agent sets up the environment (init script, progress file, feature list, initial git commit), then a Coding Agent in every subsequent session reads git logs and progress files to orient itself, picks the highest-priority incomplete feature, works on it, commits, and writes summaries. The filesystem provides continuity across context windows.
How Real Frameworks Implement the Pattern
Anthropic's Claude Agent SDK exposes the harness through a single query() function that creates the agentic loop and returns an async iterator streaming messages. The runtime is a "dumb loop." All intelligence lives in the model. Claude Code uses a Gather-Act-Verify cycle: gather context (search files, read code), take action (edit files, run commands), verify results (run tests, check output), repeat.
OpenAI's Agents SDK implements the harness through the Runner class with three modes: async, sync, and streamed. The SDK is "code-first": workflow logic is expressed in native Python rather than graph DSLs. The Codex harness extends this with a three-layer architecture: Codex Core (agent code + runtime), App Server (bidirectional JSON-RPC API), and client surfaces (CLI, VS Code, web app). All surfaces share the same harness, which is why "Codex models feel better on Codex surfaces than a generic chat window."
LangGraph models the harness as an explicit state graph. Two nodes (llm_call and tool_node) connected by a conditional edge: if tool calls present, route to tool_node; if absent, route to END. LangGraph evolved from LangChain's AgentExecutor, which was deprecated in v0.2 because it was hard to extend and lacked multi-agent support. LangChain's Deep Agents explicitly use the term "agent harness": built-in tools, planning (write_todos tool), file systems for context management, subagent spawning, and persistent memory.
CrewAI implements a role-based multi-agent architecture: Agent (the harness around the LLM, defined by role, goal, backstory, and tools), Task (the unit of work), and Crew (the collection of agents). CrewAI's Flows layer adds a "deterministic backbone with intelligence where it matters," managing routing and validation while Crews handle autonomous collaboration.
AutoGen (evolving into Microsoft Agent Framework) pioneered conversation-driven orchestration. Its three-layer architecture (Core, AgentChat, Extensions) supports five orchestration patterns: sequential, concurrent (fan-out/fan-in), group chat, handoff, and magentic (a manager agent maintains a dynamic task ledger coordinating specialists).
The Scaffolding Metaphor
The scaffolding metaphor isn't decorative. It's precise. Construction scaffolding is temporary infrastructure that enables workers to build a structure they couldn't reach otherwise. It doesn't do the construction. But without it, workers can't reach the upper floors.
The key insight: scaffolding is removed when the building is complete. As models improve, harness complexity should decrease. Manus was rebuilt five times in six months, each rewrite removing complexity. Complex tool definitions became general shell execution. "Management agents" became simple structured handoffs.
This points to the co-evolution principle: models are now post-trained with specific harnesses in the loop. Claude Code's model learned to use the specific harness it was trained with. Changing tool implementations can degrade performance because of this tight coupling.
The "future-proofing test" for harness design: if performance scales up with more powerful models without adding harness complexity, the design is sound.
Seven Decisions That Define Every Harness
Every harness architect faces seven choices:
Single-agent vs. multi-agent. Both Anthropic and OpenAI say: maximize a single agent first. Multi-agent systems add overhead (extra LLM calls for routing, context loss during handoffs). Split only when tool overload exceeds ~10 overlapping tools or clearly separate task domains exist.
ReAct vs. plan-and-execute. ReAct interleaves reasoning and action at every step (flexible but higher per-step cost). Plan-and-execute separates planning from execution. LLMCompiler reports a 3.6x speedup over sequential ReAct.
Context window management strategy. Five production approaches: time-based clearing, conversation summarization, observation masking, structured note-taking, and sub-agent delegation. ACON research showed 26 to 54% token reduction while preserving 95%+ accuracy by prioritizing reasoning traces over raw tool outputs.
Verification loop design. Computational verification (tests, linters) provides deterministic ground truth. Inferential verification (LLM-as-judge) catches semantic issues but adds latency. Martin Fowler's Thoughtworks team frames this as guides (feedforward, steer before action) versus sensors (feedback, observe after action).
Permission and safety architecture. Permissive (fast but risky, auto-approve most actions) versus restrictive (safe but slow, require approval for each action). The choice depends on deployment context.
Tool scoping strategy. More tools often means worse performance. Vercel removed 80% of tools from v0 and got better results. Claude Code achieves 95% context reduction via lazy loading. The principle: expose the minimum tool set needed for the current step.
Harness thickness. How much logic lives in the harness versus the model. Anthropic bets on thin harnesses and model improvement. Graph-based frameworks bet on explicit control. Anthropic regularly deletes planning steps from Claude Code's harness as new model versions internalize that capability.
The Harness Is the Product
Two products using identical models can have wildly different performance based solely on harness design. The TerminalBench evidence is clear: changing only the harness moved agents by 20+ ranking positions.
The harness is not a solved problem or a commodity layer. It's where the hard engineering lives: managing context as a scarce resource, designing verification loops that catch failures before they compound, building memory systems that provide continuity without hallucination, and making architectural bets about how much scaffolding to build versus how much to leave to the model.
The field is moving toward thinner harnesses as models improve. But the harness itself isn't going away. Even the most capable model needs something to manage its context window, execute its tool calls, persist its state, and verify its work.
The next time your agent fails, don't blame the model. Look at the harness.
That's a wrap!
If you enjoyed reading this:
Find me →@akshay_pachaar ✔️
Every day, I share tutorials and insights on AI, Machine Learning, and vibe coding best practices.