記事一覧へ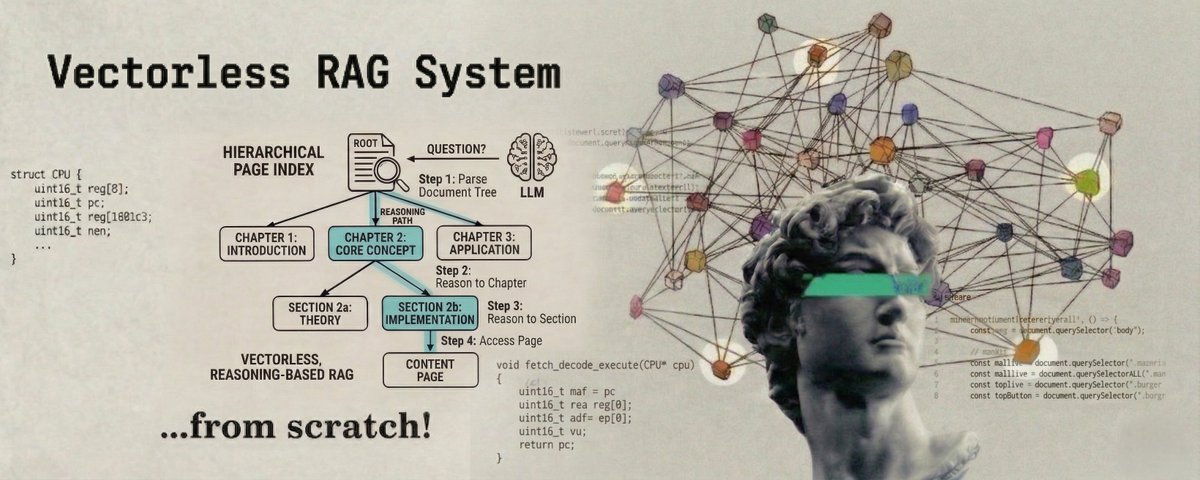
この記事では、階層的なページインデックスを使ったベクトルレス・推論ベースのRAGシステムを構築する。ドキュメントをツリーに変換し、LLMがそのツリーを推論して答えを見つける。エンベディングなし。類似検索なし。
これは、現実の情報検索とよく似ている。教科書で何かを探すとき、最初のページから全部読まない。目次を開き、適切な章を見つけ、その中のセクションを見て、必要なものに直接行く。
PageIndexは同じように機能する。ドキュメントを与えると、各ブランチがセクション、各リーフが実際のテキストであるツリーを構築する。質問をすると、LLMがそのツリーをレベルごとにナビゲートして正しい答えを見つける。
完全なコード:https://github.com/vixhal-baraiya/pageindex-rag
---
計画
コードを1行書く前の完全な計画だ。
ステップ1:ドキュメントを階層ツリーにパースする。
ドキュメントをLLMに送り、テキストをトップレベルのセクションに分割するよう頼む。次に、さらに分割するのに十分長い各セクションについて、再びLLMに送ってサブセクションを取得する。これがマルチレベルのツリーになる。短いセクションはリーフのまま。長いセクションは子を持つ内部ノードになる。
ステップ2:各ノードをボトムアップで要約する。
リーフからルートへとツリーを走査する。各リーフノードはその生テキストのLLM生成による短い要約を得る。各内部ノードは子の要約から構築された要約を得る。ルートはドキュメント全体の要約になる。
ステップ3:インデックスを保存する。
ツリーをJSONファイルにシリアライズする。これがインデックスだ。一度構築して再利用する。
ステップ4:ツリーを走査して取得する。
クエリ時に、ルートから始める。すべての子の要約をLLMに見せて、どれに入るかを聞く。その子に移動する。リーフに到達するまで繰り返す。リーフの生テキストが取得されたコンテキストだ。
ステップ5:答えを生成する。
取得したコンテキストと質問をLLMに渡して答えを得る。
---
アーキテクチャ
インデックス時(一度だけ実行):ドキュメント→セグメント化→ツリー構築→要約生成→JSONファイル保存
クエリ時(質問ごとに実行):質問→ルートから子の要約を参照→最適なブランチを選択→リーフに到達→コンテキストとしてLLMに渡す→答えを生成
---
ステップ1:プロジェクトをセットアップする
プロジェクト構造:
pageindex-rag/
pageindex/
__init__.py
node.py
parser.py
indexer.py
retriever.py
storage.py
main.py
document.md
---
ステップ2:ノードを定義する(pageindex/node.py)
ドキュメントのすべてのセクションがPageNodeになる。タイトル、生テキスト、後で生成するサマリー、子を格納する。
```python
from dataclasses import dataclass, field
from typing import Optional
@dataclass
class PageNode:
title: str
content: str # 生テキスト、リーフで設定される
summary: str # LLMが生成、インデクサーで設定される
depth: int # 0=ルート、1=セクション、2=サブセクション
children: list = field(default_factory=list)
parent: Optional["PageNode"] = None
def is_leaf(self) -> bool:
return len(self.children) == 0
```
---
ステップ3:ドキュメントをパースする(pageindex/parser.py)
ツリーを2パスで構築する。まずドキュメント全体をLLMに送り、トップレベルのセクションに分割する。次に、さらに分割する価値があるほど長いセクション(300語以上)を再度LLMに送り、サブセクションを得る。短いセクションはリーフのまま。長いものは子を持つ内部ノードになる。
_segment はセグメンテーションを行うヘルパー。parse_document はそれを2回呼ぶ:ドキュメント全体に1回、長いセクションごとに1回。
これの後、短いセクションはコンテンツを持つリーフ。長いセクションはサブセクションの子を持つ内部ノード。すべてのサマリーフィールドはこの時点では空。インデクサーが次に埋める。
---
ステップ4:サマリーを構築する(pageindex/indexer.py)
ツリーをポストオーダー(親の前に子)で走査する。各リーフは自分のコンテンツを要約する。各内部ノード(ルートやサブセクションを持つセクションなど)は子のサマリーから構築されたサマリーを得る。ポストオーダーは、親がそれを必要とする前にすべての子がサマリーを持つことを保証する。
build_summaries(root)の後、ツリーのすべてのノードに意味のあるサマリーが付く。
---
ステップ5:インデックスを保存・ロードする(pageindex/storage.py)
一度だけ構築するために、ツリーをJSONにシリアライズする。save はツリーをJSONファイルに書き込み、load はJSONから再構築する。
---
ステップ6:ツリー検索で取得する(pageindex/retriever.py)
ルートから始め、LLMが子のサマリーを読んで最適なブランチを選ぶ。その子が内部ノード(サブセクションを持つ)であれば、そのレベルで繰り返す。リーフに当たるまで続ける。whileループがどんな深さも処理する。
_pick_child:LLMに「この質問の答えを最も多く含みそうな子はどれか」を聞く。retrieve:リーフに達するまで再帰的にナビゲートする。
---
ステップ7:まとめる(main.py)
build_index:ドキュメントをパース、サマリーを構築、インデックスをJSONに保存。ask:インデックスをロード、質問でツリーを検索、コンテキストと質問でLLMに答えを生成させる。
---
インデックスの見た目
build_indexを実行した後、index.jsonを開くとこのような構造が見える:
```json
{
"title": "root",
"summary": "ドキュメントは返品、配送オプション、アカウント設定をカバーする。",
"content": "",
"depth": 0,
"children": [
{
"title": "Returns and Refunds",
"summary": "返品物の受領から14日以内に返金が処理される。",
"content": "30日以内の返品を受け付けます...",
"depth": 1,
"children": []
},
{
"title": "Shipping Options",
"summary": "国内(3〜5日)と国際配送(7〜14日)をカバーする。",
"content": "",
"depth": 1,
"children": [
{
"title": "Domestic Shipping",
"summary": "標準配達はUSPS経由で3〜5営業日かかる。",
"content": "国内はUSPS経由で配送します...",
"depth": 2,
"children": []
}
]
}
]
}
```
短いセクションは深さ1のリーフのまま。長いセクション(「Shipping Options」など)は深さ2のサブセクションの子を持つ内部ノードになる。取得はリーフに当たるまでレベルごとにナビゲートする。
---
よくある問題
LLMが間違ったブランチを選び続ける:サマリーが曖昧すぎる。_summarizeでより強力なモデルを使うか、プロンプトに詳細を追加する。
LLMのセグメンテーションがセクションを悪い場所で切る:parse_documentが長いドキュメントで実行されるとき、途中で切ることがある。セグメンテーション呼び出しのmax_tokensを増やすか、送信前にドキュメントを約3000語のチャンクに分割して修正する。
リーフのコンテンツが非常に長い:リーフに約1500トークン以上のコンテンツがある場合、SUBSECTION_THRESHOLDを下げて、より多くのセクションがサブセクションに分割されるようにする。
完全なコード:https://github.com/vixhal-baraiya/pageindex-rag
参考になったなら、リポジトリにスターをつけるのを忘れずに。
構築し続けよう。学び続けよう。
ai-thinkingai-industry
埋め込みなしの階層的推論RAGシステム
♥ 1,680↻ 238
原文を表示 / Show original
In this article we are going to build a Vectorless, Reasoning-Based RAG System using hierarchical page indexing, where a document is turned into a tree and an LLM reasons through that tree to find the answer. No embeddings. No similarity search.
This is very similar to how we search for information in real life. When you want to find something in a textbook, you do not read every page from the beginning. You open the table of contents, find the right chapter, look at the sections inside it, and go directly to the one you need.
PageIndex works the same way. You give it a document, it builds a tree from that document where each branch is a section and each leaf is the actual text, and then when you ask it a question, an LLM navigates that tree level by level to find the right answer.
Complete Code: https://github.com/vixhal-baraiya/pageindex-rag
(Don't forget to ⭐ star the repository if you found this helpful.)
The Plan
Here is the full plan before we write a single line of code.
Step 1: Parse the document into a hierarchical tree.
We send the document to the LLM and ask it to split the text into top-level sections. Then for each section that is long enough to be split further, we send it to the LLM again and get subsections. This gives us a multi-level tree. Short sections stay as leaves. Long sections become inner nodes with children.
Step 2: Summarize each node bottom-up.
We walk the tree from leaves to root. Each leaf node gets a short LLM-generated summary of its raw text. Each inner node gets a summary built from its children's summaries. The root ends up with a summary of the whole document.
Step 3: Save the index.
We serialize the tree to a JSON file. This is the index. We build it once and reuse it.
Step 4: Retrieve by walking the tree.
At query time, we start at the root. We show the LLM the summaries of all children and ask which one to go into. We move to that child. We repeat this until we reach a leaf. The leaf's raw text is our retrieved context.
Step 5: Generate the answer.
We pass the retrieved context and the question to the LLM and get our answer.
Architecture
Let's look at how data flows through the system.
Index Time (runs once)
Query Time (runs per question)
Now that we know what we are building and how all the pieces fit together, let's write the code.
Step 1: Set Up the Project
markdown
pageindex-rag/
pageindex/
__init__.py
node.py
parser.py
indexer.py
retriever.py
storage.py
main.py
document.md
Create it:
bash
mkdir pageindex-rag
cd pageindex-rag
mkdir pageindex
touch pageindex/__init__.py
Step 2: Define the Node (pageindex/node.py)
Every section of the document becomes a PageNode. It stores a title, raw text, a summary we generate later, and its children.
python
from dataclasses import dataclass, field
from typing import Optional
@dataclass
class PageNode:
title: str
content: str # raw text, populated at leaves
summary: str # generated by LLM, populated by indexer
depth: int # 0 = root, 1 = section, 2 = subsection
children: list = field(default_factory=list)
parent: Optional["PageNode"] = None
def is_leaf(self) -> bool:
return len(self.children) == 0
Step 3: Parse the Document (pageindex/parser.py)
We build the tree in two passes. First, we ask the LLM to split the whole document into top-level sections. Then, for any section long enough to be worth splitting further (more than 300 words), we send it back to the LLM and get subsections. Short sections stay as leaves. Long ones become inner nodes with children.
_segment is the helper that does one level of splitting. parse_document calls it twice: once for the whole document, and once per long section.
python
import json
import openai
from .node import PageNode
client = openai.OpenAI()
SUBSECTION_THRESHOLD = 300 # words
def _segment(text: str) -> list:
prompt = f"""Split the following text into logical sections.
Return a JSON object with a "sections" key. Each item has:
- "title": short title (5 words or less)
- "content": the text belonging to this section
Text:
{text[:8000]}"""
response = client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": prompt}],
max_completion_tokens=3000,
response_format={"type": "json_object"},
)
parsed = json.loads(response.choices[0].message.content)
return parsed.get("sections", [])
def parse_document(text: str) -> PageNode:
root = PageNode(title="root", content="", summary="", depth=0)
for item in _segment(text):
title = item.get("title", "Section")
content = item.get("content", "")
node = PageNode(title=title, content="", summary="", depth=1)
node.parent = root
word_count = len(content.split())
if word_count > SUBSECTION_THRESHOLD:
subsections = _segment(content)
if len(subsections) > 1:
for sub in subsections:
child = PageNode(
title=sub.get("title", "Subsection"),
content=sub.get("content", ""),
summary="",
depth=2,
)
child.parent = node
node.children.append(child)
else:
node.content = content # splitting gave nothing useful, keep as leaf
else:
node.content = content # short enough to stay as a leaf
root.children.append(node)
return root
After this, short sections are leaves with content. Long sections are inner nodes with subsection children. All summary fields are empty at this point. The indexer fills those in next.
Step 4: Build Summaries (pageindex/indexer.py)
We traverse the tree post-order (children before parent). Each leaf summarizes its own content. Each inner node (like root, or any section that had subsections) gets a summary built from its children's summaries. Post-order guarantees every child has a summary before its parent needs it.
python
import openai
from .node import PageNode
client = openai.OpenAI()
def _summarize(text: str, section_name: str = "") -> str:
hint = f"This is the section titled: {section_name}.\n" if section_name else ""
prompt = f"""{hint}Summarize the following in 2-3 sentences. Be specific and factual. Do not add anything not in the text.
{text[:3000]}"""
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{"role": "user", "content": prompt}],
max_completion_tokens=150,
)
return response.choices[0].message.content.strip()
def build_summaries(node: PageNode):
# post-order: children first
for child in node.children:
build_summaries(child)
if node.is_leaf():
if node.content.strip():
node.summary = _summarize(node.content, node.title)
else:
node.summary = "(empty section)"
else:
# build parent summary from children's summaries
children_text = "\n\n".join(
f"[{c.title}]: {c.summary}" for c in node.children
)
node.summary = _summarize(children_text, node.title)
After build_summaries(root), every node in the tree has a meaningful summary.
Step 5: Save and Load the Index (pageindex/storage.py)
We serialize the tree to JSON so we only build it once.
python
import json
from .node import PageNode
def save(node: PageNode, path: str):
def to_dict(n: PageNode) -> dict:
return {
"title": n.title,
"content": n.content,
"summary": n.summary,
"depth": n.depth,
"children": [to_dict(c) for c in n.children],
}
with open(path, "w") as f:
json.dump(to_dict(node), f, indent=2)
def load(path: str) -> PageNode:
def from_dict(d: dict) -> PageNode:
node = PageNode(
title=d["title"],
content=d["content"],
summary=d["summary"],
depth=d["depth"],
)
for child_dict in d["children"]:
child = from_dict(child_dict)
child.parent = node
node.children.append(child)
return node
with open(path) as f:
return from_dict(json.load(f))
Step 6: Retrieve by Tree Search (pageindex/retriever.py)
Starting at root, the LLM reads the children's summaries and picks the best branch. If that child is an inner node (it had subsections), we repeat at that level. We keep going until we hit a leaf. The while loop handles any depth.
python
import openai
from .node import PageNode
client = openai.OpenAI()
def _pick_child(query: str, node: PageNode) -> PageNode:
options = "\n".join(
f"{i + 1}. [{c.title}]: {c.summary}"
for i, c in enumerate(node.children)
)
prompt = f"""You are navigating a document tree to find the answer to a question.
Current section: "{node.title}"
Question: {query}
Children of this section:
{options}
Which child section most likely contains the answer? Reply with only the number."""
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{"role": "user", "content": prompt}],
max_completion_tokens=5,
)
try:
index = int(response.choices[0].message.content.strip()) - 1
return node.children[index]
except (ValueError, IndexError):
return node.children[0]
def retrieve(query: str, root: PageNode) -> str:
node = root
while not node.is_leaf():
if not node.children:
break
node = _pick_child(query, node)
return node.content
Step 7: Tie It Together (main.py)
python
import os
from pageindex.parser import parse_document
from pageindex.indexer import build_summaries
from pageindex.retriever import retrieve
from pageindex import storage
import openai
client = openai.OpenAI()
INDEX_PATH = "index.json"
def build_index(doc_path: str):
print("Parsing document...")
text = open(doc_path).read()
tree = parse_document(text)
print("Building summaries (this makes LLM calls)...")
build_summaries(tree)
print(f"Saving index to {INDEX_PATH}")
storage.save(tree, INDEX_PATH)
return tree
def ask(query: str) -> str:
if not os.path.exists(INDEX_PATH):
raise FileNotFoundError("Index not found. Run build_index() first.")
tree = storage.load(INDEX_PATH)
context = retrieve(query, tree)
response = client.chat.completions.create(
model="gpt-5.4",
messages=[{
"role": "user",
"content": f"Answer using only the context below.\n\nContext:\n{context}\n\nQuestion: {query}"
}],
max_completion_tokens=500,
)
return response.choices[0].message.content.strip()
if __name__ == "__main__":
# First time: build the index
build_index("document.md")
# Then query it
print(ask("Your Question"))
What the Index Looks Like
After running build_index, open index.json and you will see something like this:
json
{
"title": "root",
"summary": "Document covers returns, shipping options, and account setup.",
"content": "",
"depth": 0,
"children": [
{
"title": "Returns and Refunds",
"summary": "Refunds are processed within 14 days of receiving the returned item.",
"content": "We accept returns within 30 days...",
"depth": 1,
"children": []
},
{
"title": "Shipping Options",
"summary": "Covers domestic (3-5 days) and international shipping (7-14 days).",
"content": "",
"depth": 1,
"children": [
{
"title": "Domestic Shipping",
"summary": "Standard delivery takes 3-5 business days via USPS.",
"content": "We ship domestically via USPS...",
"depth": 2,
"children": []
},
{
"title": "International Shipping",
"summary": "International orders ship via DHL and arrive in 7-14 days.",
"content": "International shipping is available to 50+ countries...",
"depth": 2,
"children": []
}
]
},
{
"title": "Account Setup",
"summary": "Instructions for creating and verifying a new account.",
"content": "To create an account, visit...",
"depth": 1,
"children": []
}
]
}
Short sections stay as depth-1 leaves. Long sections (like "Shipping Options") became inner nodes with subsection children at depth 2. Retrieval navigates level by level until it hits a leaf.
Common Issues
The LLM keeps picking wrong branches. Your summaries are too vague. Try a stronger model in _summarize or add more detail to the prompt.
LLM segmentation cuts a section in a bad place. When parse_document runs on a long document, it sometimes splits mid-thought. Fix this by increasing max_tokens in the segmentation call, or break the document into ~3000-word chunks before sending each one.
Leaf content is very long. If a leaf has more than ~1500 tokens of content, lower SUBSECTION_THRESHOLD so more sections get split into subsections.
Complete Code: https://github.com/vixhal-baraiya/pageindex-rag
Don't forget to ⭐ star the repository if you found this helpful.
Keep building. Keep learning.