記事一覧へ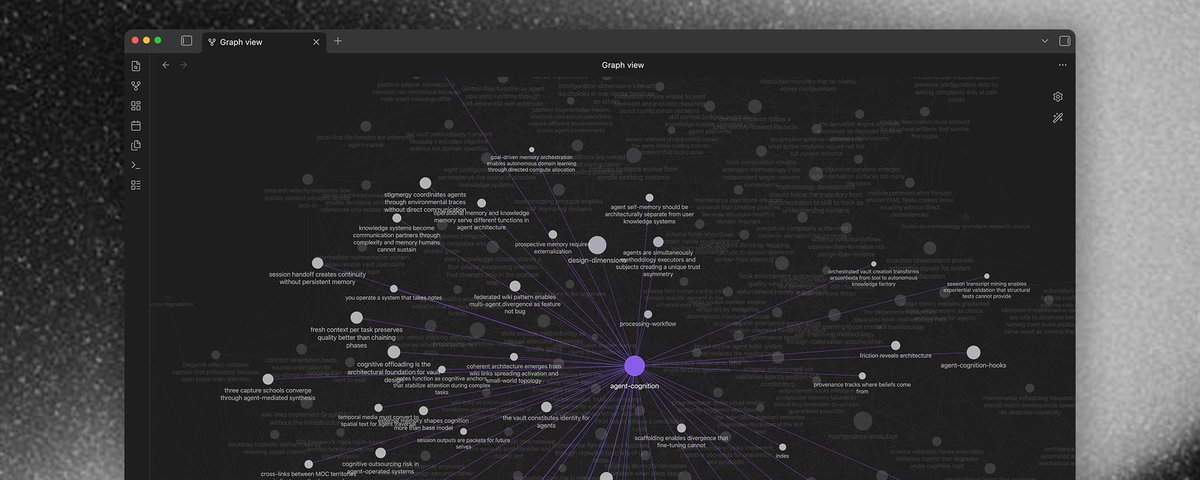
人々は構造化された知識の力を過小評価している。それはまったく新しい種類のアプリケーションを可能にする。
今、人々は何かの1つの側面をとらえるスキルを書いている。サマライズのスキル、コードレビューのスキルなど。(多くの場合)1つのファイルに1つの能力。
シンプルなタスクにはそれで十分だ。しかし本当の深みには別のものが必要だ。
認知行動パターン、愛着理論、積極的傾聴技術、感情調整フレームワークなどについての関連情報を提供するセラピーのスキルを想像してみよう。
1つのスキルファイルではそれを保持できない。
## スキルグラフ
スキルグラフとは、wikiリンクで接続されたスキルファイルのネットワークだ。
1つの大きなファイルの代わりに、互いを参照する多くの小さな組み合わせ可能な部分がある。各ファイルは1つの完全な思考、技術、またはスキルであり、[[wikiリンクがそれらの間に渡れるグラフを作成する]]。
スキルグラフはスキル発見パターンをグラフ自体の内部に再帰的に適用する。
すべてのノードにはYAMLの説明があり、エージェントはファイル全体を読まずにスキャンできる。
すべてのwikiリンクは意味を持つ。なぜなら散文に織り込まれているから。エージェントは関連するパスをたどり、重要でないものをスキップする。
**プログレッシブ・ディスクロージャー:**
インデックス → 説明 → リンク → セクション → 完全なコンテンツ
ほとんどの決定は1つのファイル全体を読む前に起こる。
## プリミティブ
必要なものはすでにすべて持っている。
- 文の中で散文として読めるwikiリンク。意味を持ち、ただの参照ではない
- エージェントが全ファイルを読まずにスキャンできるYAMLフロントマターの説明
- 関連するスキルのクラスターを探索可能なサブトピックに整理するMOC(コンテンツのマップ)
- 他のスキルへのリンクが、さらに他のスキルへとリンクし、グラフはドメインが必要とする深さまで続く
## arscontexta プラグイン
arscontextaはエージェントにスキルグラフの構築方法を教えるスキルグラフだ。
(正確にはナレッジベースの構築についてだが、それは同じことだ...)
〜250の接続されたMarkdownファイルが、エージェントに大規模なナレッジベース(別名スキルグラフ)を構築する方法を教える。
1つのスキルファイルではそれはできなかった。
しかし、認知科学、zettelkasten、グラフ理論、エージェントアーキテクチャについての相互接続された研究クレーム(/スキル)のグラフを構築すれば変わる。各部分が他の部分にリンクし、すべてが組み合わせ可能で、全体が渡れる。
## これが可能にすること
考えてみよう:
- **取引スキルグラフ**:リスク管理、マーケット心理学、ポジションサイジング、テクニカル分析。各部分が関連概念にリンクし、コンテキストが流れる
- **法律スキルグラフ**:契約パターン、コンプライアンス要件、法域の詳細、判例のチェーン。すべて1つのエントリーポイントから渡れる
- **会社スキルグラフ**:組織構造、製品知識、プロセス、オンボーディングのコンテキスト、文化、競合状況
これらはどれも1つのファイルには収まらない。しかしすべてグラフとして機能する。
## 構築方法
**簡単な方法**:arscontexta claude codeプラグインをインストールし、researchプリセットを選んで任意のトピックに向けるだけ。Markdownフォルダ構造をセットアップしてくれ、`/learn`と`/reduce`で埋めていく。
**手動の方法**(思うよりシンプルだ):
スキルグラフは`.claude/skills/`フォルダに置く必要はない。カギはエージェントに何が存在してどう渡れるかを伝えるインデックスファイルだ。
知識作業スキルグラフのインデックスがどのように見えるか:
```markdown
# knowledge-work
エージェントにも思考のためのツールが必要だ。zettelkasten、evergreen notes、記憶術が人間に考えるための外部構造を与えたように、エージェントが操作するナレッジシステムはエージェントに考えるための外部構造を与える。
## 統合
各部分がどのように合わさるかについての議論:
- [[system is the argument]] — 実証を伴った哲学。すべてのノート、リンク、MOCがそれが描く方法論を示す
- [[coherent architecture emerges from wiki links]] — 構造とは何か、なぜ機能するか、エージェントがどう渡るか、いつ見直すかに答える基本的な三角形
## トピックMOC
ドメインは7つの相互接続された領域に分かれる:
- [[graph-structure]] — wikiリンク、トポロジー、リンクパターンが渡れるナレッジグラフを作る方法
- [[agent-cognition]] — エージェントが外部構造を通じてどう考えるか:渡り方、セッション、注意の限界
- [[agent-cognition-hooks]] — フックの実施、構成、自動品質の認知科学
- [[agent-cognition-platforms]] — プラットフォーム能力ティア、抽象化レイヤー、コンテキストファイルアーキテクチャ
- [[discovery-retrieval]] — 説明、プログレッシブ・ディスクロージャー、検索がコンテンツの発見と読み込みを可能にする方法
- [[processing-workflow]] — スループット、セッション、ハンドオフが作業をシステム通して動かす方法
## クロスドメインクレーム
- [[forced engagement produces weak connections]] — 生産性よりも活動のための強制的なエンゲージメントが浅いつながりを生み出す(統合なしの蓄積が浅いナレッジグラフを生み出すのと同様)
## 探求が必要なこと
- 欠如:人間とエージェントの渡りパターンの比較。エージェントは異なるアーキテクチャを必要とするか?
- スケーリングの限界:どのシステムサイズで人間によるキュレーションが機能しなくなるか?
```
インデックスはルックアップテーブルではなく注意を向けるエントリーポイントだ。エージェントはそれを読み、ランドスケープを理解し、現在の会話に重要なリンクをたどる。
各リンクされたファイルはスタンドアロンの方法論的クレーム(=スキル)だ。散文内のwikiリンクがいつ、なぜそれに従うべきかをエージェントに伝える。
MOC(コンテンツのマップ)はグラフが大きくなった時にサブトピックを整理する。
## 進化
スキルはコンテキストエンジニアリング、基本的には重要な場所に注入されるキュレートされた知識だ。
スキルグラフはその次のステップだ。
1回の注入の代わりに、エージェントはナレッジ構造をナビゲートし、現在の状況が必要とするものを正確に引き込む。
これは指示に従うエージェントとドメインを理解するエージェントの違いだ。
arscontextaはナレッジシステムを構築するためにこれをやるclaude codeプラグインだ。エージェントが渡って、あなたのワークフローに本当に合うローカルナレッジシステムを導き出す249ファイルの構造化された知識。
使ってみて、そして他のすべてのためにスキルグラフを構築してほしい。
— ハインリッヒ
ナレッジグラフエージェントharness-designAI
Skill Graphs > SKILL.md — 構造化された知識グラフの力
♥ 8,747↻ 889
原文を表示 / Show original
people underestimate the power of structured knowledge. it enables entirely new kinds of applications
right now people write skills that capture one aspect of something. a skill for summarizing, a skill for code review and so on. (often) one file with one capability
thats fine for simple tasks but real depth requires something else
imagine a therapy skill that provides relevant information about cognitive behavioral patterns, attachment theory, active listening techniques, emotional regulation frameworks and so on
a single skill file cant hold that
skill graphs
a skill graph is a network of skill files connected with wikilinks
instead of one big file you have many small composable pieces that reference each other. each file is one complete thought, technique or skill and [[wikilinks between them create a traversable graph]]
a skill graph applies the same skill discovery pattern recursively inside the graph itself
every node has a yaml description the agent can scan without reading the whole file
every wiki link carries meaning because its woven into prose so the agent follows relevant paths and skips what doesnt matter
progressive disclosure:
index → descriptions → links → sections → full content
most decisions happen before reading a single full file
the primitives
you already have everything you need
wikilinks that read as prose in sentences, so they carry meaning not just references
yaml frontmatter with descriptions so the agent can scan without reading full files
MOCs (maps of content) that organize clusters of related skills into navigable sub-topics
skill links to other skills which link to other skills and the graph goes as deep as the domain requires
arscontexta plugin
arscontexta is a skill graph that teaches your agent how to build skill graphs
(okay actually its about building knowledge bases but thats the same thing...)
~250 connected markdown files that teach an agent how to build a massive knowledge base aka skill graph for you
one skill file couldnt do that
but things change if you build a graph of interconnected research claims (/skills) about cognitive science, zettelkasten, graph theory, agent architecture where each piece links to others, each one composable and the whole thing is traversable
what this enables
think about it:
a trading skill graph: risk management, market psychology, position sizing, technical analysis, each piece linked to related concepts so context flows between them
a legal skill graph: contract patterns, compliance requirements, jurisdiction specifics, precedent chains, all traversable from one entry point
a company skill graph: org structure, product knowledge, processes, onboarding context, culture, competitive landscape
none of these fit in one file but all of them work as graphs
how to build one
the easy way: install the arscontexta claude code plugin, pick the research preset and point it at any topic
it sets up the markdown folder structure for you and then you fill it with /learn and /reduce
the manual way its simpler than you think
a skill graph doesnt need to live in your .claude/skills/ folder. the key is an index file that tells the agent what exists and how to traverse it
heres what an index looks like for a knowledge work skill graph:
# knowledge-work
Agents need tools for thought too. Just as Zettelkasten, evergreen notes, and memory palaces gave humans external structures to think with, agent-operated knowledge systems give agents external structures to think with.
## Synthesis
Developed arguments about how the pieces fit together:
- [[the system is the argument]] — philosophy with proof of work; every note, link, and MOC demonstrates the methodology it describes
- [[coherent architecture emerges from wiki links spreading activation and small-world topology]] — the foundational triangle that answers what structure looks like, why it works, how agents navigate it, and when to reassess
...
## Topic MOCs
The domain breaks into seven interconnected areas:
- [[graph-structure]] — how wiki links, topology, and linking patterns create traversable knowledge graphs
- [[agent-cognition]] — how agents think through external structures: traversal, sessions, attention limits
- [[agent-cognition-hooks]] — hook enforcement, composition, and cognitive science of automated quality
- [[agent-cognition-platforms]] — platform capability tiers, abstraction layers, context file architecture
- [[discovery-retrieval]] — how descriptions, progressive disclosure, and search enable finding and loading content
- [[processing-workflow]] — how throughput, sessions, and handoffs move work through the system
...
## Cross-Domain Claims
- [[forced engagement produces weak connections]] — the social analog of accretion over productivity: forcing engagement for activity's sake produces shallow connections, just as accumulation without synthesis produces shallow knowledge graphs
## Explorations Needed
- Missing: comparison between human and agent traversal patterns. do agents need different architectures?
- Scaling limits: at what system size does human curation fail?
the index isnt a lookup table its an entry point that points attention. the agent reads it, understands the landscape and follows the links that matter for the current conversation
each linked file is a standalone methodology claim (= skill). heres what one node looks like:
see how the wikilinks inside the prose tell the agent when and why to follow them
an map of contents (MOCs) organize sub-topics when the graph gets larger.
the evolution
skills are context engineering, basically curated knowledge injected where it matters
skill graphs are the next step
instead of one injection the agent navigates a knowledge structure, pulling in exactly what the current situation requires
this is the difference between an agent that follows instructions and an agent that understands a domain
arscontexta is a claude code plugin that does this for building knowledge systems. 249 files of structured knowledge the agent traverses to derive a local knowledge system that really fits your workflow
go use it and build skill graphs for everything else
heinrich